

Resilience testing is a crucial non-functional testing method used to evaluate how well a system can withstand and recover from failures, crashes, or unexpected disruptions. Unlike standard performance testing, resilience testing focuses on ensuring system stability under adverse conditions. It plays a vital role in software testing services by validating the robustness of applications in real-world scenarios. Leveraging chaos engineering tools like Chaos Monkey, Gremlin, and LitmusChaos, QA teams can simulate failures to test system durability. This blog explores resilience testing tools, key techniques, and industry best practices for building failure-resistant, high-availability systems.
What’s Next? Keep reading to discover:
🚀 Advanced Resilience: Boost system robustness with chaos engineering.
🚀 Testing Gaps: Traditional tests miss real-world failures.
🚀 Faster Recovery: Improve downtime and healing speed.
🚀 DevOps Integration: Use chaos tools in CI/CD pipelines.
🚀 Future Trends: AI and automation in chaos testing.
What is Resilience Testing in Software Development?
Resilience testing is a non-functional testing type that checks how well a software system can recover and continue functioning during and after failures, such as crashes, outages, or hardware faults. It ensures software stability under stress and validates fault tolerance in real-world scenarios.
Key Goals and Objectives of Resilience Testing:
- Validate Fault Tolerance: Confirm that the software can withstand and respond to unexpected failures like network outages, server crashes, or hardware malfunctions.
- Maintain Core Functionality: Ensure that essential services remain available and operational even when some components fail.
- Simulate Real-World Failures: Use chaos engineering tools (e.g., Chaos Monkey, Gremlin) to replicate real incident scenarios and evaluate the system's response.
- Improve Recovery Mechanisms: Assess the system’s ability to detect issues and recover automatically or through fallback solutions.
- Strengthen System Reliability: Boost long-term system dependability by continuously testing resilience under various stress and failure conditions.
How Resilience Testing Differs from Performance Testing
While both resilience testing and performance testing are essential non-functional testing types, they serve different goals in the software testing lifecycle. Often misunderstood as similar, these testing approaches focus on distinct system qualities.
Resilience testing checks how well a system recovers from failures, such as crashes or outages, and ensures continuous operation under stress. It’s crucial for validating fault tolerance, failure handling, and testing resilience using tools like Chaos Monkey and Gremlin.
Real-World Scenarios Where Resilience Testing Prevented Major Failures
Resilience testing is a vital non-functional testing approach that helps organizations detect weaknesses before they cause system failures. Below are three key use cases where resilience testing tools and chaos engineering prevented major disruptions:
1. Netflix and Chaos Monkey Testing
- Overview: Netflix pioneered chaos engineering with Chaos Monkey, a gremlin tool for chaos engineering that randomly terminates cloud instances to test fault tolerance.
- Implementation: This resilience testing method simulates unexpected failures in production environments, forcing systems to recover gracefully.
- Why it matters: Prevents outages by ensuring availability, validating resilience tests, backup systems, and boosting customer satisfaction and performance.
2. Shopify’s Kubernetes Chaos Engineering
- Overview: Shopify employs Kubernetes chaos engineering tools like LitmusChaos to test microservice failures and network faults.
- Implementation: These resilience testing tools introduce controlled disruptions to validate system recovery and fault handling in their e-commerce platform.
- Why it matters: Enhances system robustness during high-traffic events, ensuring smooth user experiences through improved software quality assurance testing.

3. Financial Services Using Gremlin for Fault Injection
- Overview: Financial firms use Gremlin chaos engineering to simulate outages and network delays within critical transaction systems.
- Implementation: Gremlin injects faults to test the system’s ability to maintain consistency and reliability under failure conditions.
- Why it matters: This software testing service strengthens security and minimizes downtime, crucial for maintaining trust and regulatory compliance.
Core Principles of a Resilient System
A resilient system is essential in software testing and software quality assurance testing to ensure continuous operation despite failures. The core principles that guide resilience testing include:
- Fault Tolerance: The ability to handle faults without total system failure, validated through non-functional testing like stress testing software and software security testing.
- Graceful Degradation: Maintaining partial functionality during failures, a key focus of performance testing in software testing, to ensure the user experience isn’t disrupted.
- Self-Healing: Automatic detection and recovery from faults, often tested with integration testing software and other software for testing tools.
- Redundancy and Failover: Using backup components and failover mechanisms to maintain availability, verified through software testing services.
- Observability and Monitoring: Continuous monitoring enables early detection and resolution of issues, crucial during resilience testing for maintaining the system.
Step-by-Step Guide to Performing Resilience Testing
Performing resilience testing is critical in software testing services to ensure systems can withstand and recover from failures. Here’s a step-by-step approach:
- Define Test Objectives: Identify the critical components and failure scenarios that require focus. Set clear goals to assess fault tolerance and recovery capabilities.
- Select Appropriate Resilience Testing Tools: Choose tools like Chaos Monkey, Gremlin, or LitmusChaos that suit your environment for fault injection and disruption simulation.
- Prepare the Test Environment: Create a controlled setting that mirrors production, ensuring safe and effective execution of software for testing resilience under real-world conditions.
- Design Fault Injection Scenarios: Develop test cases that simulate network failures, server crashes, or resource exhaustion. This helps in evaluating the system’s behavior during disruptions.
- Execute Tests and Monitor Metrics: Run tests while tracking key indicators like system uptime, response times, and error rates. Use monitoring tools for comprehensive software performance testing.
- Analyze Results and Fix Issues: Identify weaknesses from test outcomes and prioritize fixes to enhance fault tolerance and robustness.
- Repeat Regularly: Continuous resilience testing as part of non-functional testing ensures ongoing system reliability.
Popular Tools Used for Resilience Testing
Resilience testing relies on specialized tools to simulate failures and verify how software systems withstand and recover from adverse conditions. Below are some of the most effective resilience testing tools, along with their key features and how they contribute to building robust systems.

Chaos Monkey – Random Instance Termination
Chaos Monkey, a pioneering tool in chaos engineering, was introduced by Netflix to test system resilience under real-world failure conditions. It randomly terminates cloud instances or services without warning, allowing teams to evaluate how software testing services handle abrupt disruptions. By injecting failures into production-like environments, it supports resilience testing by ensuring systems can self-heal and maintain uptime.
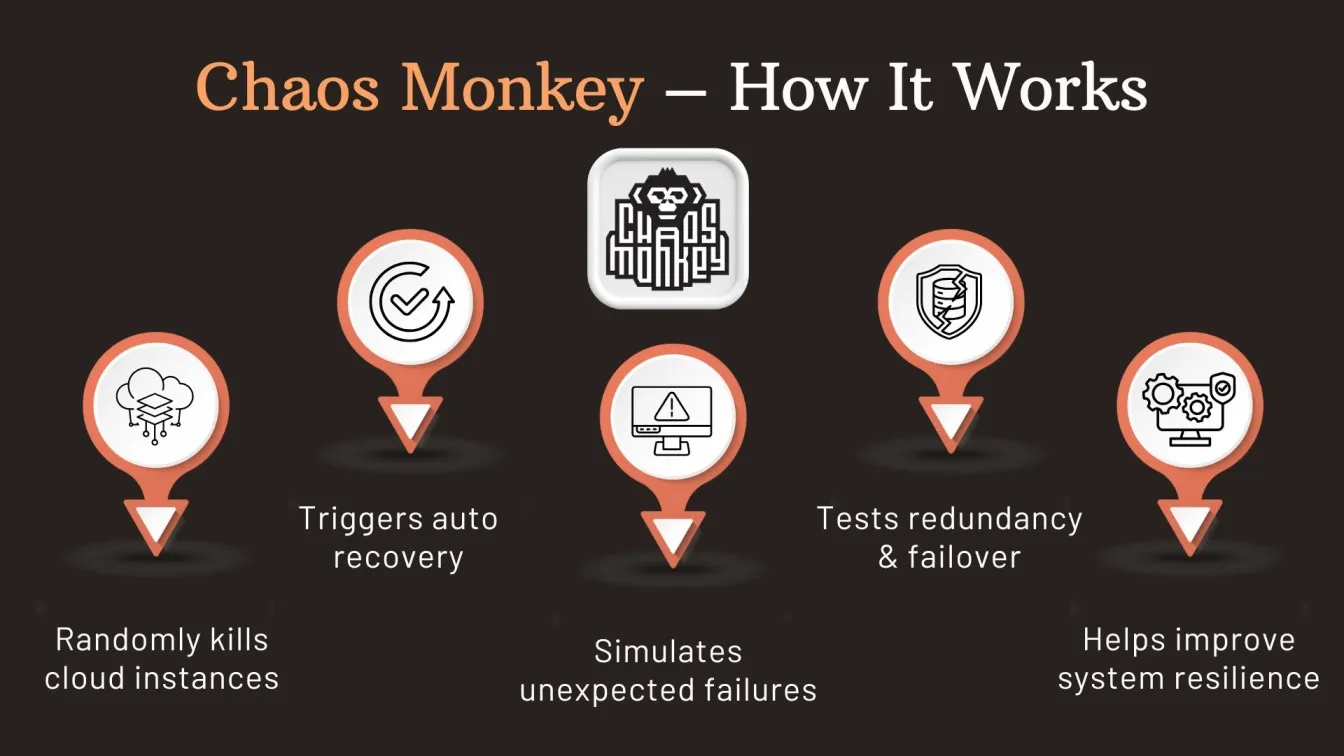
Key Features:
- Random instance termination to simulate failure
- Compatible with AWS Chaos Monkey and Kubernetes Chaos Monkey setups
- Validates auto-recovery and service redundancy
- Helps with non-functional testing and planning for disaster recovery
Role in Resilience Testing:
This tool is critical in testing software for fault tolerance, making it a key component in software quality assurance testing and performance testing in software testing strategies focused on stability and reliability.
Gremlin – Controlled Fault Injection
Gremlin is a powerful chaos engineering tool designed for safe and systematic resilience testing. It allows teams to simulate real-world outages like CPU spikes, network delays, and shutdowns. Gremlin excels in controlled fault injection, enabling developers to test their software for disaster recovery strategies without impacting users.
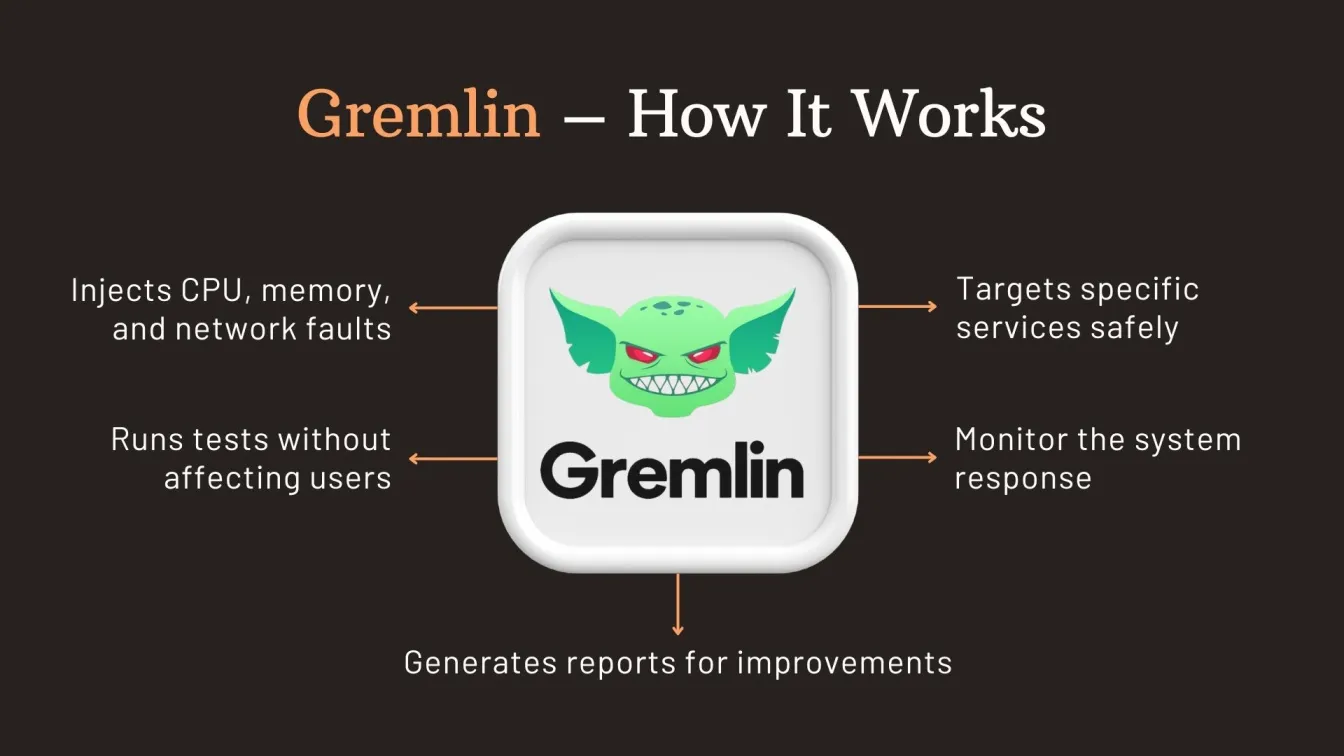
Key Features:
- User-friendly interface with customizable attack scenarios
- An extensive library of failure types for non-functional testing
- Supports both cloud and on-prem infrastructure
- Integration with monitoring and software testing tools
Role in Resilience Testing:
Gremlin empowers software testing services to proactively identify and fix weaknesses. It complements software performance testing by verifying system robustness under controlled chaos, ensuring greater fault tolerance and system uptime.
LitmusChaos – Kubernetes Chaos Testing
LitmusChaos is an open-source chaos engineering Kubernetes tool tailored for resilience testing in containerized environments. It simulates real-world faults in Kubernetes clusters to validate recovery strategies and overall system stability.
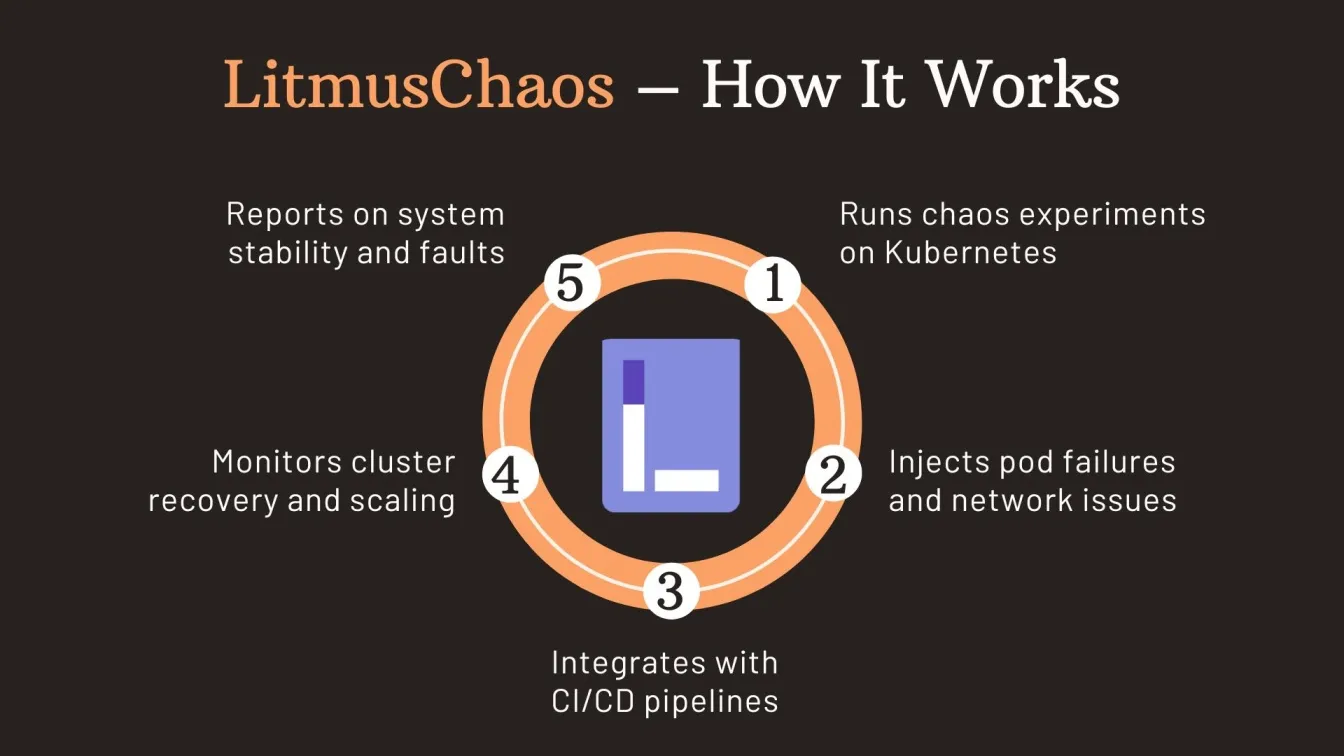
Key Features:
- Chaos workflows tailored for Kubernetes clusters simulate chaotic conditions during the testing process.
- Predefined experiments uncover potential failures and performance issues under heavy load.
- CI/CD integration enables automated resilience tests within the software development lifecycle.
- Reports validate backup systems and assess the impact on customer satisfaction and economic strategy.
Role in Resilience Testing:
LitmusChaos helps teams ensure reliable Kubernetes deployments through consistent non-functional testing. It supports software testing service providers in identifying configuration weaknesses and validating auto-scaling, service mesh recovery, and container restarts during disruptions.
Toxiproxy – Network Fault Simulation
Toxiproxy is a dynamic proxy tool used in resilience testing to simulate network issues like latency, bandwidth throttling, or connection drops. Designed for testing software under stress, it helps validate how distributed applications handle degraded network conditions.
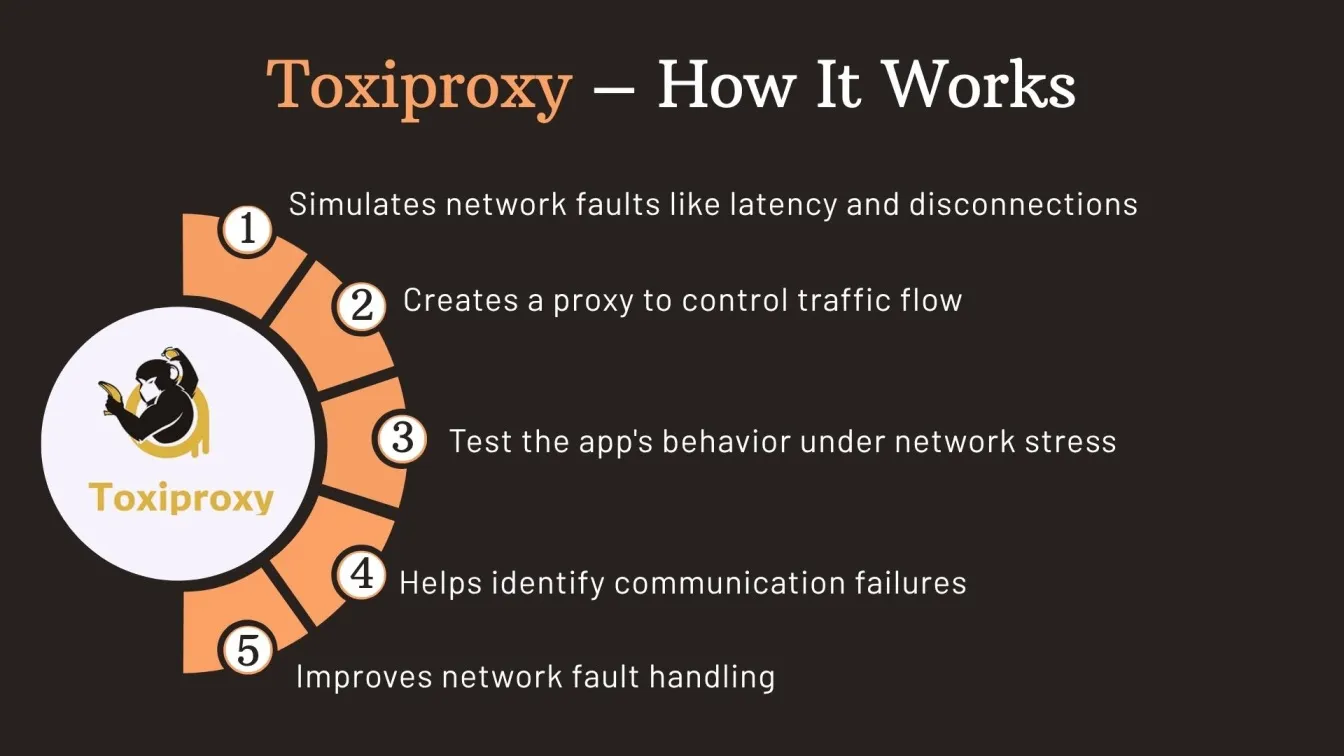
Key Features:
- Simulates a wide range of realistic network faults and latency issues
- Easily configurable via flexible and developer-friendly RESTful APIs
- Works seamlessly with integration testing software setups and frameworks
- Suitable for use in both development and production-like testing environments
Role in Resilience Testing:
Toxiproxy plays a crucial role in software quality assurance testing, particularly for microservices and cloud-native applications. It strengthens load testing software and non functional testing in software testing strategies by revealing hidden weaknesses in communication layers.
Jepsen – Consistency Testing for Distributed Systems
Jepsen is a framework designed for resilience testing and software security testing in distributed systems. It tests the correctness of the database and distributed system operations under faults, helping validate consistency models and isolation guarantees.
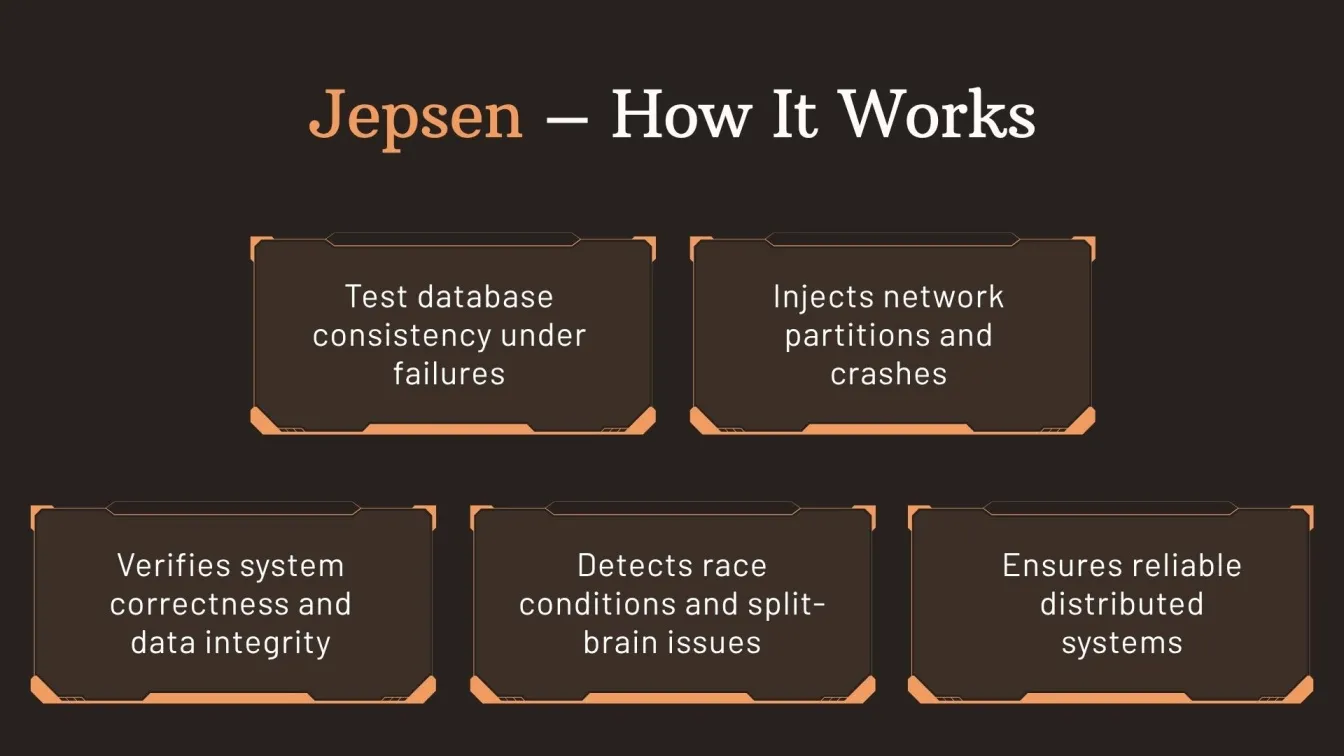
Key Features:
- Simulates complex network partitions and deliberate process crashes effectively
- Test data consistency and replication accuracy across multiple distributed nodes
- Supports a wide range of systems like databases, queues, and transactional platforms
- Automates both functional and non-functional testing to uncover concurrency-related issues
Role in Resilience Testing:
Jepsen enhances software testing services by ensuring data integrity under failure. It’s a core tool for validating software performance testing and durability in mission-critical systems, making it essential for testing resilience in distributed architectures.
Metrics to Track During and After Resilience Testing
Tracking the right metrics is crucial in resilience testing to evaluate how well a system recovers and maintains stability during failures. These metrics help validate the system’s fault tolerance, performance under stress, and overall software quality assurance.
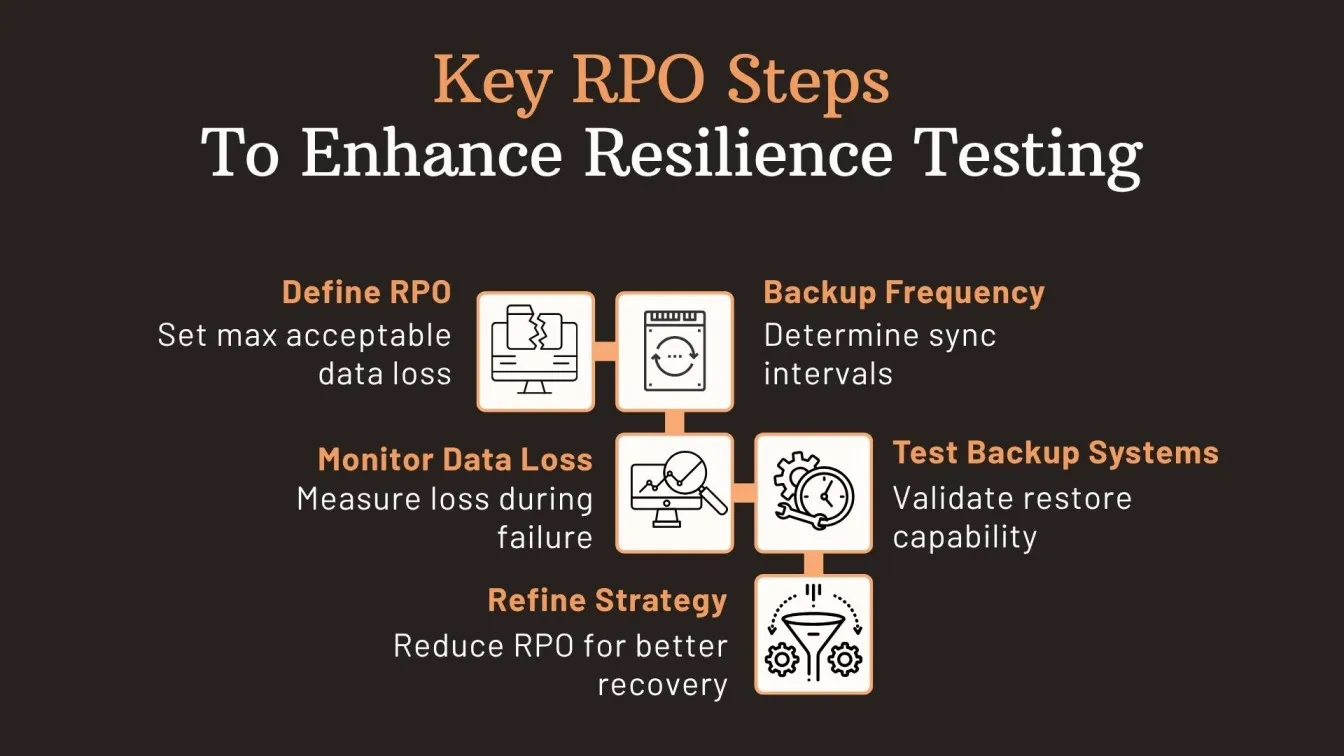
Key Metrics to Monitor:
- Recovery Time Objective (RTO): Measures the time taken by the system to recover and return to normal operations after a failure. A lower RTO indicates better resilience.
- Recovery Point Objective (RPO): Indicates the amount of data loss acceptable during a disruption. It helps assess how frequently backup or sync mechanisms are working.
- System Uptime & Availability: Tracks the percentage of time the software remains functional. Helps ensure high availability even during chaos engineering or stress testing software scenarios.
- Error Rate: Monitors the frequency of system errors or failed requests during and after testing resilience under adverse conditions.
- Latency and Throughput: These software performance testing metrics reflect how fast the system responds and how much load it handles under test-induced disruptions.
Common Challenges and How to Overcome Them in Resilience Testing
Resilience testing ensures software can handle unexpected failures, but it comes with its own set of difficulties.

Key Challenges in Resilience Testing:
- Simulating Realistic Failures: Creating real-world fault scenarios like node crashes or network outages demands advanced chaos engineering tools and a precise setup.
- Environment Parity Issues: Testing environments often differ from production, leading to inaccurate results. Use production-like test environments to close this gap.
- Tool Complexity and Integration: Some resilience testing tools are hard to configure and don’t integrate well with CI/CD. Prefer tools like Gremlin or LitmusChaos that offer better usability.
- Lack of Observability: Without proper monitoring, diagnosing failures is difficult. Use observability platforms to track and log system behavior during tests.
- Team Skill Gaps: Limited knowledge in non-functional testing and chaos engineering can hinder testing efforts. Provide training and practical exposure to upskill your teams.
Conclusion: Building Robust Systems Through Continuous Resilience Testing
Resilience testing plays a critical role in developing software that can withstand unexpected failures and maintain seamless operation. By regularly incorporating resilience testing into the software testing lifecycle, teams can uncover hidden vulnerabilities and strengthen system fault tolerance. This proactive approach ensures software not only meets functional needs but also goes beyond regular testing to excel in non-functional areas like performance and security, aligning with the core goal of resilience testing to enhance overall software quality assurance.

Utilizing specialized resilience testing tools and chaos engineering techniques allows organizations to simulate real-world disruptions effectively. Continuous resilience testing builds confidence in system reliability, reduces downtime, and minimizes the risk of major failures in production environments. Ultimately, investing in resilience testing empowers businesses to deliver dependable software services that meet user expectations and stand strong against unpredictable challenges.

Frugal Testing is a leading SaaS application testing company known for its AI-driven test automation services. Among the services offered by Frugal Testing are cloud-based test automation services that help businesses improve testing efficiency, ensure software reliability, and achieve cost-effective, high-quality product delivery.
People Also Ask
What signs indicate a system’s lack of resilience?
Frequent crashes, slow recovery, data loss, and inability to handle or recover from failures indicate poor resilience.
What’s the difference between fault tolerance and resilience?
Fault tolerance keeps a system running despite faults, while resilience focuses on recovery and maintaining service continuity after failures.
Can you automate resilience testing in development workflows?
Yes, by integrating chaos testing, fault injection, and recovery checks into CI/CD pipelines.
What are resilience indicators?
Metrics like recovery time, error rates, system uptime, and degraded service response help assess system resilience.
Why is observability important during resilience testing?
Observability helps detect, diagnose, and understand failures quickly, enabling faster and more effective recovery.





.webp)
