

As software systems grow more complex and interconnected, traditional testing methods sometimes fall short in ensuring their reliability. Chaos Engineering, a cutting-edge approach, is changing how we think about testing and system resilience.
By deliberately introducing disruptions into a system, Chaos Engineering reveals weaknesses that might otherwise go unnoticed, helping teams build stronger, more resilient applications.
📌 Why You Should Read This Blog:
Discover how Chaos Engineering is revolutionizing software testing practices.
Learn how to leverage Chaos Engineering to proactively identify system vulnerabilities.
Gain insights into building more resilient software systems through strategic testing.
What is Chaos Engineering? 🌪️

Chaos Engineering is a proactive testing methodology that involves deliberately injecting faults and disruptions into a system to identify potential weaknesses and enhance its resilience. Unlike traditional testing approaches that focus on ensuring systems work as expected, Chaos Engineering assumes that failures are inevitable in complex, distributed systems.
By simulating unexpected events such as server crashes, network failures, or latency spikes Chaos Engineering allows teams to observe how their systems behave under stress and to uncover vulnerabilities that might otherwise go unnoticed.
This approach helps organizations identify areas where their systems are fragile and provides insights into how to strengthen them. As a result, Chaos Engineering not only improves the reliability of software but also enhances the overall user experience by reducing downtime and mitigating the impact of unforeseen issues.
In today’s digital landscape, where uptime and performance are critical, Chaos Engineering is becoming an essential practice for organizations that prioritize
robustness and resilience in their software systems.
Is Chaos Engineering Necessary in Software Testing? 🤔

In the fast-growing world of software development, the necessity of Chaos Engineering in testing is becoming increasingly evident. Traditional testing methods are crucial for validating that systems behave as expected under normal conditions. However, they often fall short in uncovering how a system will respond to unexpected disruptions, such as server failures, network delays, or sudden spikes in traffic. This is where Chaos Engineering steps in 🌪️.
Chaos Engineering is necessary because it helps proactively identify and address potential vulnerabilities in complex, distributed systems. By deliberately introducing chaos such as random faults or simulated failures; teams can observe how their systems respond to these stressors in real-time. This practice reveals weaknesses that traditional testing might miss, such as hidden dependencies, random events, bottlenecks, or single points of failure.
The value of Chaos Engineering lies in its ability to build system resilience. In today’s environment, where even minor disruptions can lead to costly downtime or negative impacts on millions of users, ensuring that a system can handle unexpected failures is critical. Chaos Engineering not only prepares systems to withstand these challenges but also creates a culture of continuous improvement and learning within development teams.
How Chaos is Integrated into Traditional Software Testing 🛠️
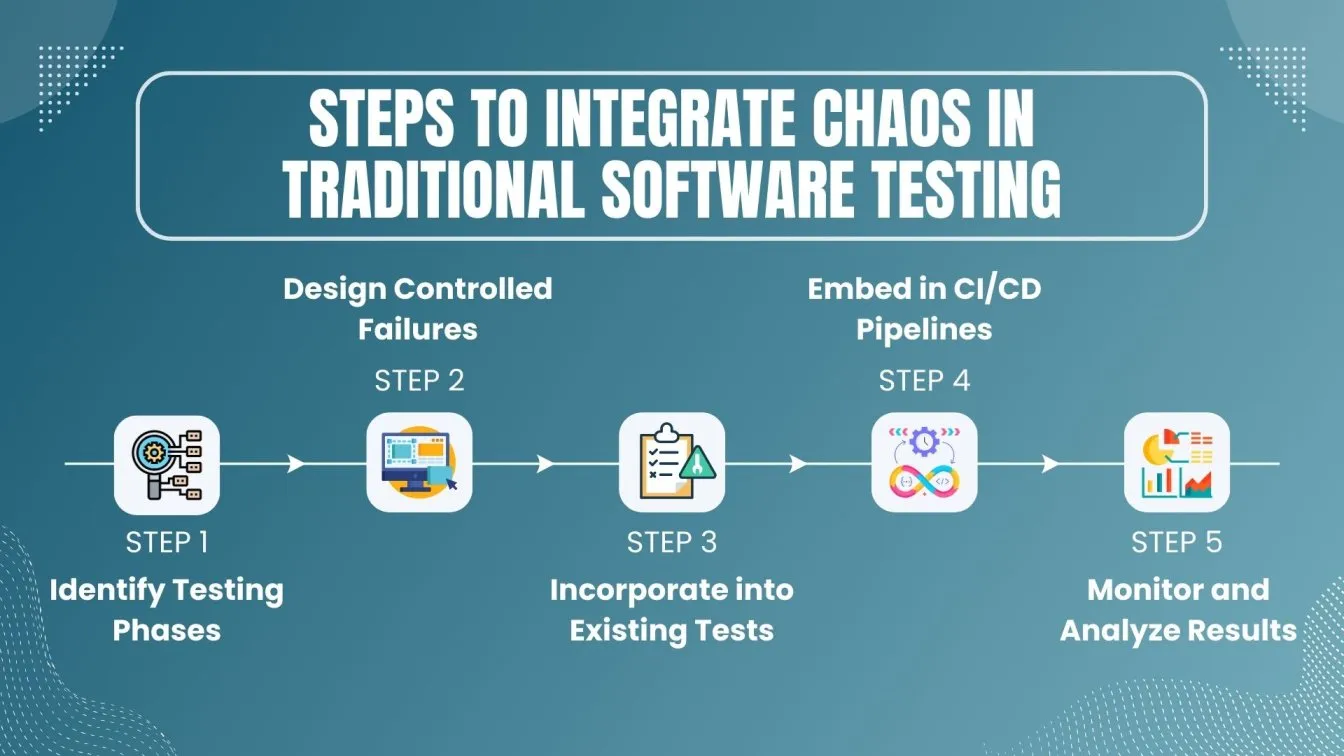
To effectively ensure system resilience and performance, Chaos Engineering is increasingly being integrated into traditional software testing practices. Here’s how it enhances each phase:
- Introducing Controlled Failures During Testing 🌐
Chaos Engineering introduces controlled disruptions, such as server crashes and network interruptions, at various testing stages to evaluate how well the system performs under stress and identify weaknesses that traditional tests might miss.
- Enhancing Unit and Integration Tests 🧩
By integrating Chaos Engineering with unit and integration testing, teams can simulate failures to stress-test individual components and their interactions. This approach helps uncover potential points of failure and ensures components can handle unexpected issues.
- Augmenting Stress Testing 🚀
Traditional stress tests are improved with Chaos Engineering by replicating real-world scenarios, like traffic surges or hardware malfunctions. This provides valuable insights into the system's ability to endure and recover from high-stress situations.
- Integrating into CI/CD Pipelines 🔄
Chaos experiments are incorporated into CI/CD pipelines, allowing continuous testing of new builds and deployments. This integration helps verify that updates do not compromise system stability, maintaining resilience throughout the development lifecycle.

Popular Software Testing Tools for Chaos Engineering 🔧

📌 Description: One of the pioneers in Chaos Engineering, Chaos Monkey randomly terminates instances in production to ensure systems can handle unexpected failures.
📌 Use Case: Ideal for testing the resilience of cloud-based services and ensuring that instances can be terminated without affecting overall system performance.
- Powerful Chaos Toolkit
📌 Description: An open-source toolkit designed for creating and running chaos experiments. It supports various platforms and integrates with different monitoring tools.
📌 Use Case: Ideal for teams that require flexibility and customization in their chaos experiments across different environments.
- ChaosBlade
📌 Description: An open-source chaos engineering tool developed by Alibaba. It provides various chaos experiments for both cloud and on-premises environments.
📌 Use Case: Useful for teams seeking a robust tool with a wide range of failure scenarios and integration options.
What are the Testing Frameworks of Chaos Engineering?
Chaos Engineering uses tools like Chaos Toolkit, Gremlin, Chaos Mesh, LitmusChaos, and Pumba to simulate disruptions and test system resilience, each offering unique features suited for different environments. Choosing the right tool depends on your infrastructure and testing needs.

- Overview: An open-source framework that simplifies the process of creating, managing, and running chaos experiments. It supports a wide range of systems and integrates easily with existing monitoring and observability tools.
- Key Features:
- 🔌 Extensible with plugins for cloud providers, containers, and more.
- 📝 Declarative approach to defining chaos experiments.
- 🔄 Integrates with CI/CD pipelines for continuous chaos testing.
- Use Case: Ideal for teams looking for a flexible and extensible framework to run chaos experiments across diverse environments.
- Overview: A comprehensive Chaos Engineering platform offering a suite of tools to simulate real-world outages. Gremlin provides an intuitive UI and CLI for orchestrating chaos experiments.
- Key Features:
- 🔌 Wide range of failure scenarios, including CPU spikes, memory exhaustion, and network latency.
- 🔄 Supports both pre-production and production environments.
- Detailed reporting and analytics to track the impact of experiments.
- Use Case: Best for organizations seeking a commercial, enterprise-grade solution for Chaos Engineering with robust support and features.
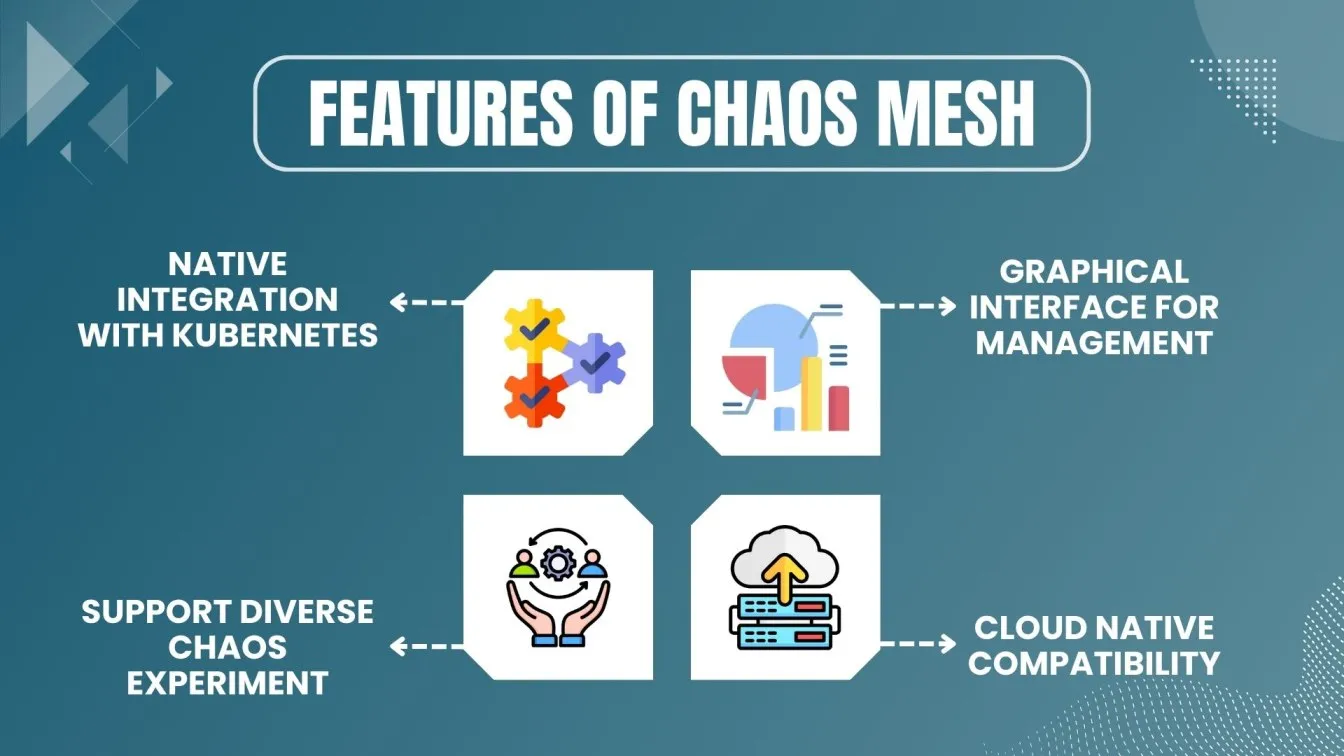
- Overview: An open-source chaos engineering framework for Kubernetes, Chaos Mesh provides powerful chaos experiments specifically designed for cloud-native software applications.
- Key Features:
- 🧩 Native integration with Kubernetes for containerized environments.
- 🧪 Supports experiments like pod failure, CPU failure, network partition, and IO chaos.
- 📊 Provides a graphical interface for managing and observing chaos experiments.
- Overview: Another Kubernetes-native Chaos Engineering framework, LitmusChaos offers extensive chaos experiments and integrates with CI/CD pipelines to automate chaos testing.
- Key Features:
- 🧬 A wide array of predefined chaos experiments for Kubernetes.
- 🔗 Integration with popular CI/CD tools like Jenkins and GitLab.
- 📈 Rich observability and monitoring integration for real-time insights.
- Use Case: Suitable for DevOps teams that need a Kubernetes-focused framework with strong automation and integration capabilities.
What are the Chaos Engineering Principles applicable for Software Testing?
Chaos Engineering principles provide a framework for systematically testing and improving system resilience by introducing disruptions. These principles help ensure that software can maintain stability and performance under unexpected conditions. Here are the key principles:

- Embrace Failure as a Learning Opportunity
📉 Principle: Accept that failures are inevitable in complex systems and use them as opportunities to learn and improve.
🔍 Application in Testing: Design tests that intentionally introduce failures to observe how systems react, identify weaknesses and implement improvements.
- Build Hypotheses Around Steady State Behavior
📊 Principle: Understand what "normal" looks like for your system and define it clearly.
🎯 Application in Testing: Before introducing chaos, establish core principles for performance, reliability, and other key metrics. Use these baselines to compare against the system's behavior during and after chaos experiments.
- Run Experiments in Production
🌐 Principle: Conduct chaos experiments in production environments to observe real-world impacts.
🚀 Application in Testing: Although traditional testing often occurs in staging environments, Chaos Engineering encourages safe experimentation in production to validate that systems perform reliably under actual conditions.
Common Challenges Involved with Chaos Testing Software 🚧
Chaos testing can offer significant benefits, but it also comes with its own set of challenges. Addressing these hurdles is crucial for successful implementation and effective outcomes. Here’s a look at some common challenges and their mitigations:

Chaos testing in live production environments carries the risk of unintended disruptions or outages. To mitigate this, start with low-impact experiments, clearly define their scope, and implement safeguards like circuit breakers or feature flags to minimize potential harm.
Designing chaos experiments effectively requires a thorough understanding of the system’s architecture, dependencies, and failure modes. This can be challenging given the complexity of modern systems. Start with simpler experiments and gradually increase their complexity, utilizing chaos engineering tools and frameworks that offer templates and automation.
Measuring the impact of chaos experiments can be difficult, particularly in complex systems where failures may have cascading effects. Effective monitoring and observability tools are crucial to track performance metrics throughout the experiments, allowing for ongoing refinement to enhance system resilience.
Adopting chaos testing can face cultural resistance, as teams may fear breaking systems, disrupting workflows, or facing blame for failures. To overcome this, foster a culture that views failures as opportunities for learning, educate teams on the benefits of chaos engineering, and begin with less invasive experiments to build confidence.
What is the difference between Chaos Testing and Chaos Engineering?

What are the metrics for Chaos Testing?
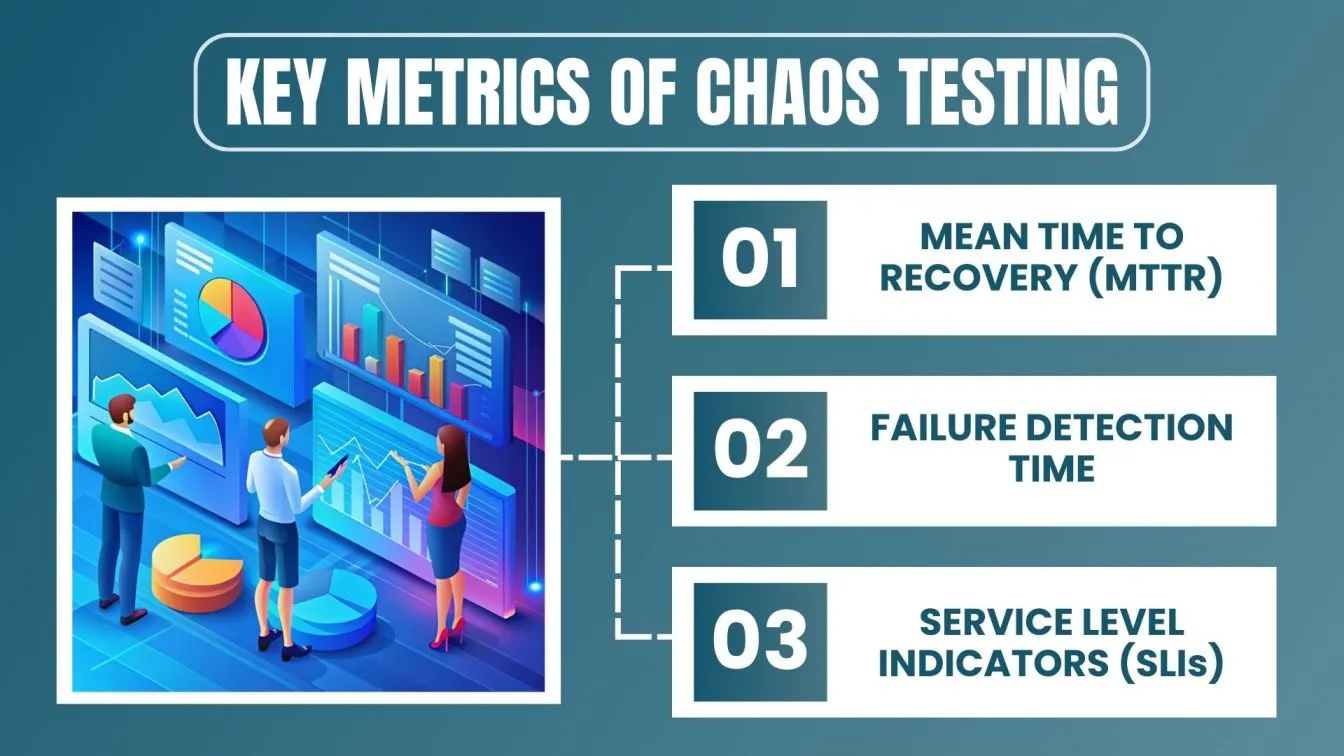
Key Metrics for Chaos Testing 📊
- Mean Time to Recovery (MTTR)
The average time it takes for a system to recover from a failure or disruption caused by a chaos experiment. A lower MTTR indicates that the system can quickly restore normal operations after a failure, which is critical for maintaining uptime and reliability.
- Failure Detection Time
The time it takes for monitoring and alerting systems to detect a failure introduced during chaos testing. Fast detection is essential for minimizing the impact of failures and initiating recovery processes promptly.
- Service Level Indicators (SLIs)
Metrics that directly measure the performance of a service, such as latency, error rate, and throughput, during and after chaos experiments. Monitoring SLIs helps assess whether the system meets its service level objectives (SLOs) under failure conditions.
Is Software Testing using Chaos Engineering on Decline?
Despite its growing popularity in recent years, some concerns have arisen about whether the use of Chaos Engineering in software testing is on the decline. The reality is more nuanced:

- Evolving Practices, Not Decline
Chaos Engineering isn’t declining but evolving. As organizations mature in its adoption, the initial excitement may diminish, leading to more integrated practices. Companies now embed Chaos Engineering into regular operations, shifting from experimental testing to consistent testing in actual production systems.
- Increased Automation and Tooling
The rise of automation and advanced tooling has made Chaos Engineering more accessible. Many organizations have automated chaos experiments within CI/CD pipelines, making them routine rather than headline-grabbing events, especially in cloud-based applications and DevOps environments.
- Focus on Resilience Over Chaos
There’s a shift toward broader resilience engineering, with Chaos Engineering as a key strategy. This shift isn’t a decline but a sign of more comprehensive resilience strategies, ensuring a seamless user experience even in faulty scenarios.
- Testing in Production
Testing in production has become essential as teams simulate chaos conditions in actual production systems. Failure injection testing within chaos engineering testing frameworks helps uncover vulnerabilities not visible under normal conditions.
- Collaboration Between Teams
Chaos Engineering’s success depends on collaboration between teams. Developers, operations, and business units must align chaos testing with business objectives. Platforms like Chaos Conf and Chaos Engineering Slack foster collaboration and best practices.
Quick Recap: Embrace the Chaos 🌟
In today's fast-paced digital world, where software systems are increasingly complex, traditional testing alone isn't enough. 🛠️ Chaos Engineering steps in as a proactive solution, helping to identify hidden weaknesses and strengthen applications by simulating real-world disruptions.
By deliberately injecting failures, Chaos Engineering ensures that your systems are not just surviving but thriving under pressure. 🌐 This approach is key to delivering high-performance, reliable software that can handle the unpredictable nature of modern technology.
As uptime and user experience become top priorities, integrating Chaos Engineering isn't just a nice-to-have it's a must. 🔒 Embracing this mindset allows teams to build systems that are not only resilient but also continually improving.
Chaos Engineering is more than a testing strategy; it's a cultural shift towards innovation and performance. By adopting this approach, you empower your organization to confidently face the future, knowing your systems are ready for anything.






