
LinkedIn runs on massive distributed systems that demand seamless performance, even at global scale. To achieve this, the platform relies on cloud scalability and modern practices that extend beyond just technology, influencing business scalability and long-term growth.
Whether it’s managing software scalability or optimizing scalability in business, every layer of the infrastructure must adapt to rising demands. Lessons from sectors like distributed energy systems highlight the importance of resilience. With advanced cloud computing scalability, LinkedIn ensures reliability, speed, and user satisfaction, proving that scaling isn’t just technical it’s a strategic advantage in today’s digital landscape.
💡 Here’s what you’ll learn:
📌 How LinkedIn tests are distributed at a global scale.
📌 Cloud scalability practices ensure platform reliability.
📌 Fault tolerance with chaos engineering techniques.
📌 Leveraging automation and Apache JMeter for load testing.
📌 Site Reliability Engineering driving seamless performance.
Introduction to LinkedIn’s Distributed Systems Testing
LinkedIn operates on some of the world’s most complex distributed systems, powering real-time communication, recommendations, and large-scale data processing for millions of users. Ensuring performance and reliability in such an environment requires more than traditional testing; it demands a focus on cloud scalability and adaptability across every layer.
Much like distributed energy systems balance demand and supply seamlessly, LinkedIn’s architecture is designed to handle continuous growth while maintaining stability. The platform also relies on advanced monitoring systems and LinkedIn automation tool like DealsFlow to streamline operations, improve efficiency, and support large-scale performance management.

Scalability is not limited to technology alone. Business scalability plays an equally vital role in driving sustainable growth. To meet evolving user needs, the company invests heavily in software scalability, ensuring applications can scale without performance bottlenecks. This is where cloud computing scalability comes in, enabling LinkedIn to expand resources dynamically and maintain user experience at peak demand. By aligning distributed systems testing with both business and technical goals, LinkedIn demonstrates how modern platforms can achieve unmatched resilience.
Its approach reflects a larger trend in the digital ecosystem, where scalability and reliability define success. Understanding LinkedIn’s strategies provides valuable insights into building platforms that are not only functional but also future-ready.
Why Distributed Systems Need Specialized Testing Approaches
Modern platforms like LinkedIn rely heavily on distributed systems to deliver seamless experiences at scale. Unlike traditional monolithic applications, these systems operate across multiple nodes, data centers, and cloud environments, which introduces new layers of complexity. Ensuring reliability in such an ecosystem demands specialized testing approaches that go beyond functional validation.
A key reason is cloud scalability as demand fluctuates, the system must dynamically allocate resources without affecting performance. Similarly, principles from distributed energy systems highlight the need for balance and fault tolerance, making scalability a business as well as a technical priority.

In fact, scalability in business is directly linked to how effectively the underlying infrastructure handles growth. Testing must also focus on software scalability to detect performance bottlenecks early. With cloud computing scalability, distributed systems gain elasticity, but this flexibility must be validated through:
- Stress Testing: Simulates peak loads to identify performance bottlenecks.
- Fault Tolerance Checks: Ensures system continues running during failures.
- Reliability Assessments: Validates stable performance under all conditions.
Without these measures, even minor defects can cascade into large-scale failures. By investing in distributed systems testing, organizations can ensure that platforms remain resilient, high-performing, and future-ready. This specialized focus transforms scalability and reliability from challenges into sustainable competitive advantages.
Core Principles of LinkedIn’s Testing Methodology
At LinkedIn’s scale, testing is not just about functionality it’s about building trust in highly complex distributed systems. The company’s testing methodology is guided by principles that ensure stability, cloud scalability, and user satisfaction across millions of interactions daily.
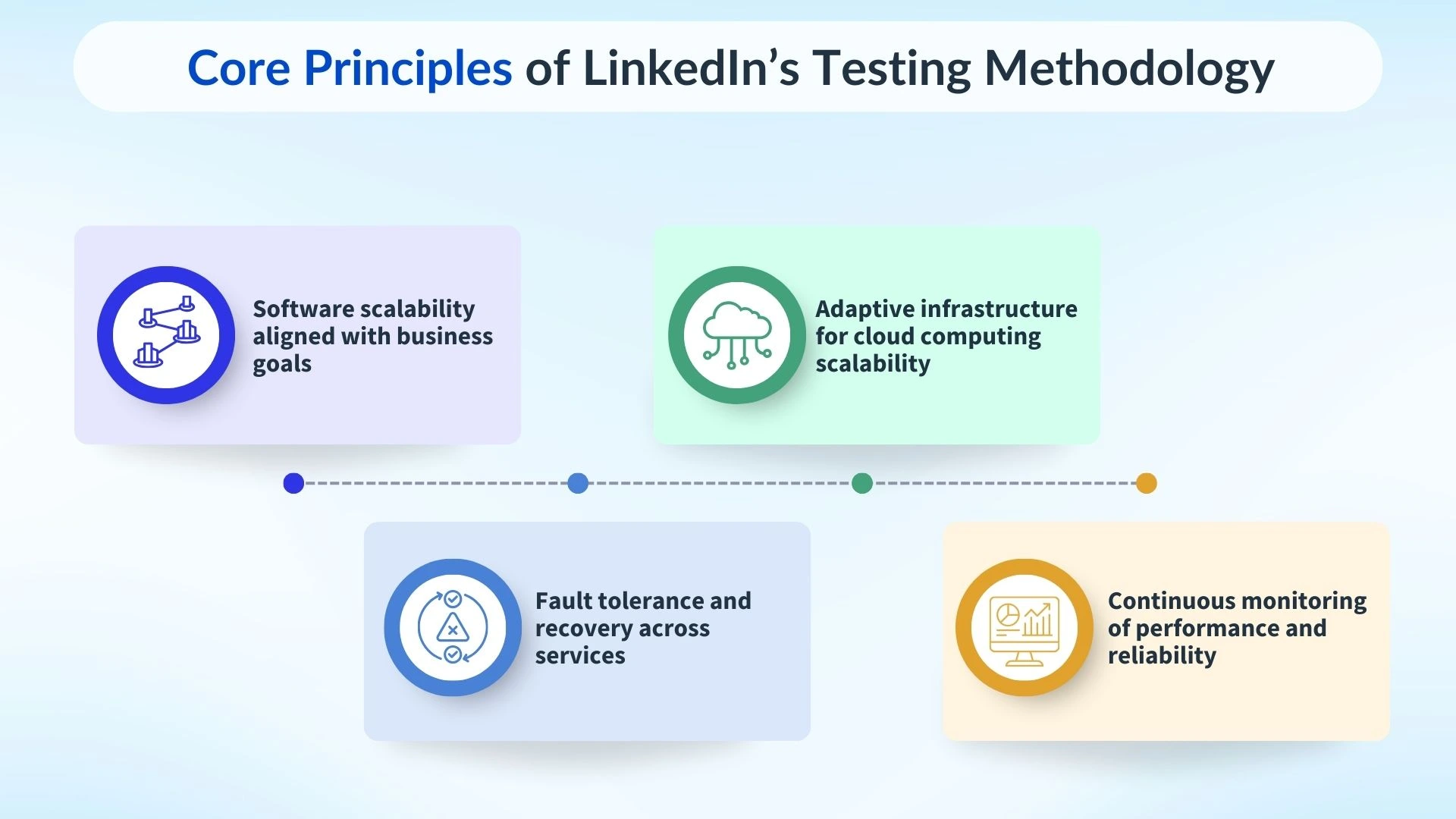
Key Principles:
- Designing for Software Scalability:
- Applications must handle exponential growth without compromising speed or performance.
- Supports business scalability and long-term sustainability.
- Every feature aligns with broader goals of scalability in business.
- Cloud Computing Scalability:
- Infrastructure dynamically adapts to workload variations.
- Testing includes normal performance and unexpected surges.
- Principles from distributed energy systems guide balance and load management.
- Reliability and Fault Tolerance:
- Emphasizes fault tolerance, recovery mechanisms, and continuous monitoring.
- Ensures distributed systems withstand failures without service disruptions.
By embedding these core principles into its testing lifecycle, LinkedIn demonstrates how robust testing frameworks transform complexity into resilience. Its methodology provides a blueprint for any organization striving to deliver seamless experiences while scaling technology and business together.
Key Challenges in Testing Distributed Systems
Testing distributed systems involves handling large-scale architectures, multi-node interdependencies, and diverse workloads. Ensuring cloud scalability, software scalability, and system reliability under real-time conditions is critical for seamless global performance.
Testing distributed systems like LinkedIn’s is inherently complex due to:
- Scale: Managing millions of concurrent users and global traffic.
- Interdependencies: Coordinating multiple nodes, services, and data centers.
- Diverse Workloads: Handling varied tasks, requests, and real-time data processing.
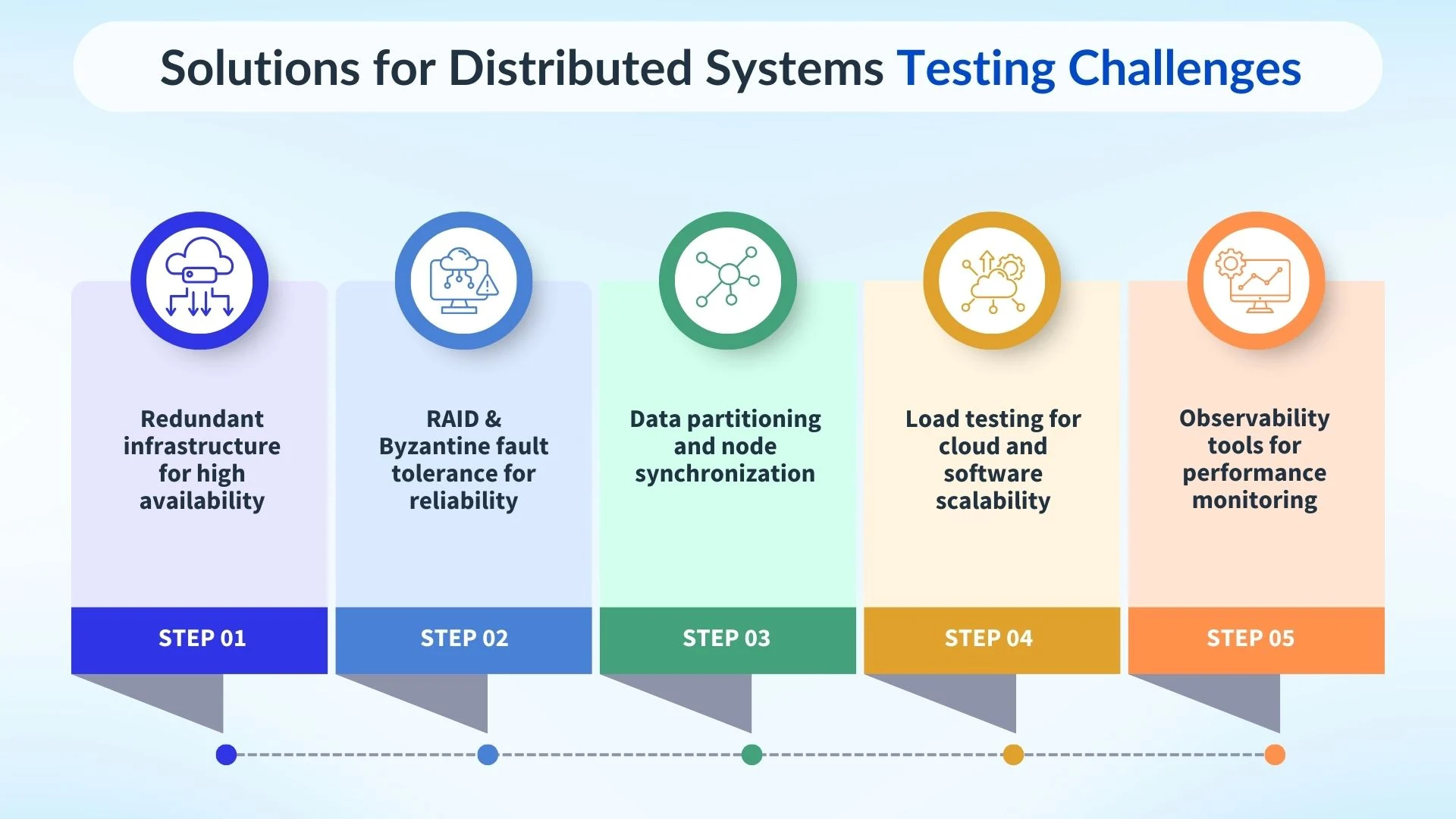
Unlike single-node applications, distributed architectures must account for failures, data flow interruptions, and unpredictable user demands. Achieving cloud scalability while ensuring software scalability and business scalability introduces unique challenges that standard testing cannot address.
Effective validation must focus on performance, resilience, and adaptability ensuring that cloud computing scalability supports continuous growth without service disruption.
Fault Tolerance and High Availability
One of the biggest challenges in distributed systems is achieving fault tolerance while maintaining high availability.
- Even minor component failures can cascade into larger disruptions.
- Testing validates redundancy, recovery systems, and failover mechanisms.
This ensures reliability at scale. It also helps build and maintain user trust.
Data Consistency and Synchronization
ML feature data supports synchronization testing during modernization initiatives, ensuring consistent performance and data accuracy across globally distributed nodes. Maintaining data consistency and synchronization across multiple nodes and regions is another challenge:
- Distributed systems face latency issues, replication delays, and conflicting updates.
- Testing frameworks validate synchronization mechanisms.
- Aligns scalability in business with accuracy in data.
Performance and consistency are essential for seamless global operations.
Testing Tools and Frameworks Used by LinkedIn
LinkedIn relies on a mix of advanced testing frameworks and automation practices to ensure performance across distributed systems. These tools not only validate functionality but also enhance software scalability, cloud computing scalability, and overall system reliability.
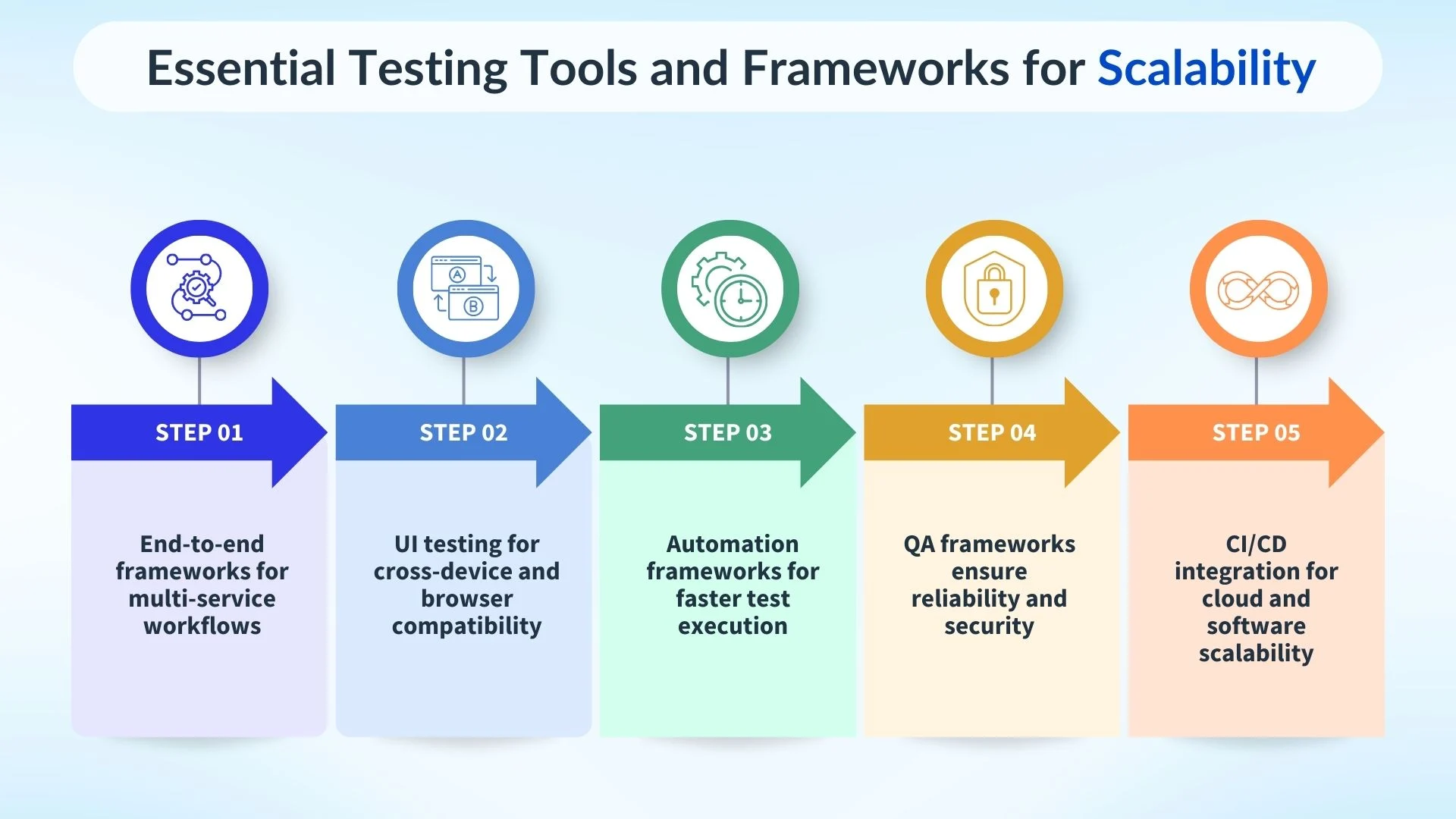
By combining multiple frameworks with continuous integration, LinkedIn turns testing into a strategic enabler of growth and resilience. These testing tools also support observability, load testing, and fault tolerance, ensuring distributed systems remain robust and scalable under high user demand.
Testing Strategies for Distributed Systems
Validating distributed systems requires testing strategies far beyond traditional QA. LinkedIn ensures that cloud scalability, software scalability, and business scalability work in harmony to deliver reliable global experiences.
Testing focuses on:
- Functional correctness: Ensures all services work accurately across nodes.
- System resilience: Validates stability under high load and failures.
- Cloud computing scalability: Confirms infrastructure adapts to real-world traffic.
Scalability and Load Testing at Global Scale
LinkedIn uses advanced load testing strategies to ensure distributed systems handle massive user traffic efficiently.
- JMeter load testing, Gatling load testing, and Java load testing.
- Simulates millions of concurrent interactions.
- Highlights bottlenecks across distributed services.
- Specialized load testing tools and services ensure peak traffic resilience.
- Supports software performance testing for scalable infrastructure and applications.
These strategies ensure cloud scalability, software scalability, and system reliability under real-world conditions.
Chaos Engineering and Failure Injection
Proactive failure simulations help LinkedIn validate system resilience and maintain high availability globally.
- Simulates outages, node crashes, and latency spikes.
- Validates resilience and fault tolerance.
- Paired with observability and monitoring for real-time recovery insights.
- Transforms testing into proactive defense against unpredictable disruptions.
This approach strengthens fault tolerance, reduces downtime, and enhances overall distributed systems performance.
Lessons Learned from LinkedIn’s Testing Practices
LinkedIn’s experience provides valuable lessons for achieving both cloud scalability and business scalability.
- Continuous Testing: Software scalability must be tested continuously.
- Cloud Computing Scalability: Elastic infrastructure requires rigorous validation via testing frameworks, load testing, and observability tools.
- Reliability: Fault tolerance, chaos engineering, and real-time monitoring maintain stability.
- Strategic Enablement: Testing transforms challenges of scale into competitive advantages.
These lessons reinforce how robust testing drives platform reliability, scalability, and operational efficiency globally.
Future of Distributed Systems Testing in Enterprise Platforms
The future of enterprise platforms depends on resilient, adaptive, and scalable distributed systems to meet global demand efficiently.

- Strong CI/CD Pipelines: Accelerates innovation while preserving reliability.
- Mandatory Cloud Scalability: As organizations expand globally, scaling becomes essential.
- Integration of Software and Business Scalability: Technical growth translates into measurable business outcomes.
- AI-driven Automation & Continuous Monitoring: Advanced frameworks maintain performance at scale.
- Load Testing & Real-time Observability: Ensures platforms adapt to fluctuating demand.
- Chaos Engineering & Fault Tolerance: Standard practices for unpredictable failures.
This approach ensures enterprise platforms remain future-ready, reliable, and capable of supporting global operations.
Conclusion: Building Reliable and Scalable Systems Through Testing
LinkedIn proves that building a reliable professional networking platform depends on more than scale; it requires a disciplined approach to testing. By focusing on system reliability and software reliability, the company ensures seamless experiences across diverse Internet architectures. Its distributed testing practices validate performance, scalability, and resilience under real-world conditions.
In practice, LinkedIn’s Distributed Systems Architecture leverages OLTP data-stores, real-time validation, and cloud computing scalability to achieve global performance goals. By applying data partitioning, elastic cloud deployments, and Apache JMeter load testing across availability zones, engineers proactively identify failure modes and minimize blast radius during outages. Chaos engineering scenarios, Site Reliability Engineering practices, and OLTP data-stores validation ensure resilience under stress.
ML models, rule-based systems, and tracking system insights combine with human review processes and analytics team collaboration, creating a holistic framework for Distributed Systems testing. This integrated approach reinforces reliability while enabling sustainable, scalable growth.
LinkedIn applies best practices from top software testing companies, combining AI-driven test automation services, load testing services, functional testing solutions, and QA testing services for enterprises. It also leverages open-source tools like Apache JMeter alongside cloud-based test automation services to ensure reliable, scalable, and resilient distributed systems.
People Also Ask
👉 What makes LinkedIn’s distributed systems testing approach unique compared to other enterprises?
LinkedIn combines cloud computing scalability, software scalability, and business scalability with specialized distributed systems testing. Its focus on fault tolerance, real-time validation, and global load handling ensures high reliability and seamless user experiences at scale.
👉 Which tools and frameworks are most effective for testing large-scale distributed systems?
LinkedIn leverages end-to-end testing frameworks, UI testing frameworks, automation and QA testing frameworks, along with CI/CD pipelines, Apache JMeter, Gatling, and Java-based load testing tools for comprehensive validation.
👉 How does LinkedIn perform scalability and load testing for millions of active users?
Using Apache JMeter, Gatling, and Java load testing, LinkedIn simulates millions of concurrent interactions, identifies bottlenecks, validates cloud and software scalability, and ensures consistent performance across all services.
👉 What role does chaos engineering play in improving LinkedIn’s distributed systems reliability?
Chaos engineering injects failures, latency spikes, and node crashes to test fault tolerance, resilience, and recovery mechanisms, ensuring LinkedIn’s distributed systems maintain high availability under unpredictable conditions.
👉 How does LinkedIn use monitoring and observability to validate distributed systems performance?
LinkedIn employs observability dashboards, real-time monitoring tools, and metrics tracking to detect bottlenecks, validate system health, and ensure performance, reliability, and seamless operation across its distributed infrastructure.





.webp)
