

Perplexity AI is an AI-powered answer engine built to move beyond traditional search results and deliver direct, citation-backed answers. Instead of asking users to scan multiple links, it combines real-time information retrieval with advanced AI models to surface concise, verifiable insights in a conversational format.
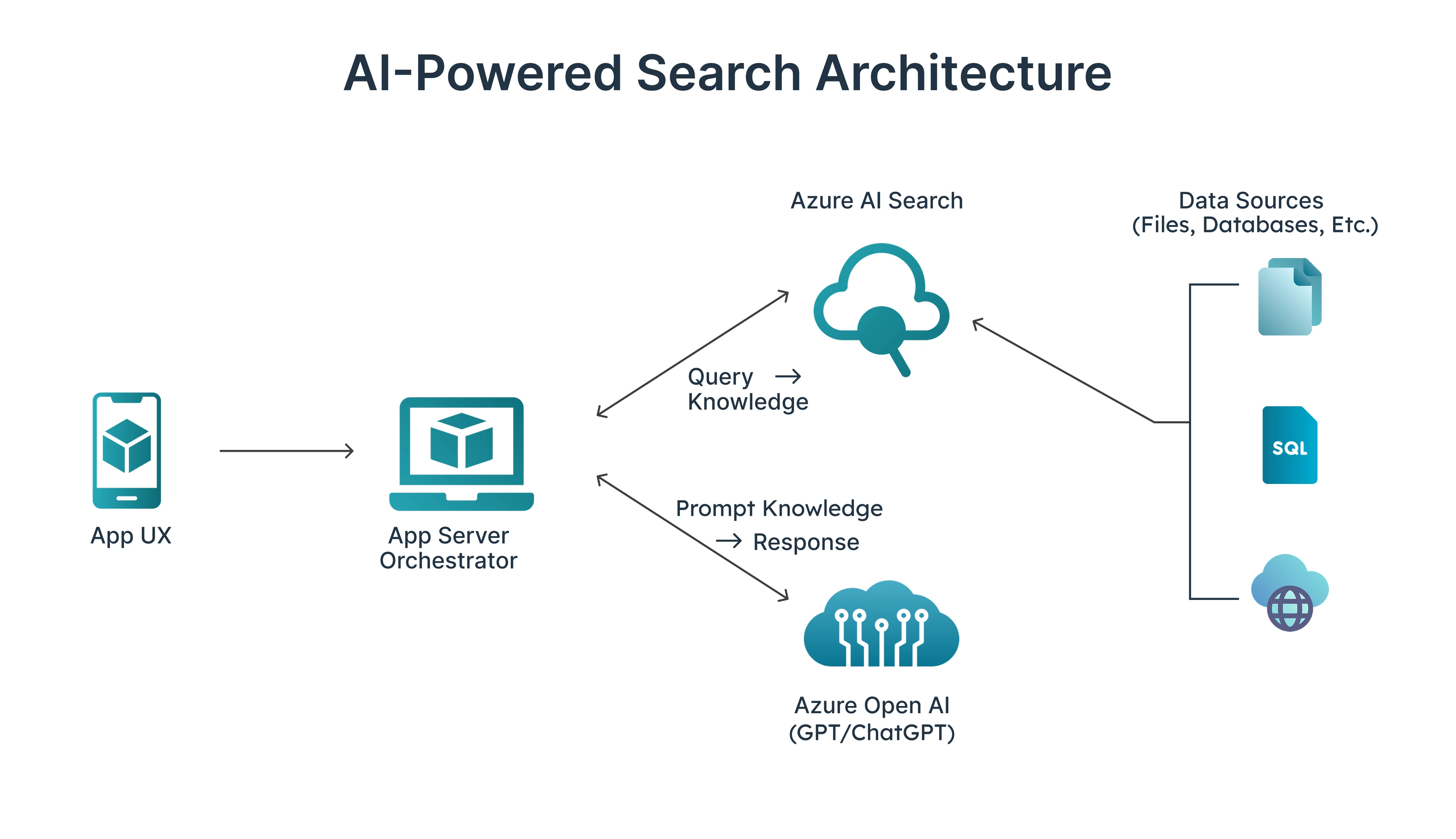
At a high level, Perplexity’s architecture is designed around a few core principles:
- Uses large language models (LLMs) alongside real-time web retrieval
- Applies Retrieval-Augmented Generation (RAG) to reduce hallucinations
- Supports a conversational interface for natural follow-up questions
- Retrieves live data through on-demand crawling and trusted APIs
- Prioritizes source citations and transparency in every response
Introduction to AI Search and Perplexity’s Architecture
AI-powered search is moving fast—from static keyword matching to dynamic, conversational discovery. Platforms like Perplexity AI are redefining how CEOs, CTOs, and technology leaders consume information. Instead of ten blue links, users now expect direct answers, live citations, and real-time relevance.User habits and preferences have changed very quickly, as research shows 68% of internet users trust information from AI as much or more than organic search results.
At Frugal Testing, we analyze these shifts closely because they influence enterprise SEO, AI discovery systems, and content strategy. Search today is no longer just about traffic; it acts as a decision-support layer embedded into workflows, copilots, and dashboards.
Understanding Perplexity’s architecture provides a clear view of how modern AI search retrieves, ranks, and validates real-time web data.
Evolution from traditional search engines to AI-powered search
Traditional search engines relied on search indexes, lexical search, and ranking algorithms such as PageRank and BM25. Queries were matched against indexed documents, with relevance driven mainly by keywords and backlinks.
AI-powered search changes this flow:
- Queries are interpreted using natural language processing
- Retrieval combines lexical search, vector search, and hybrid pipelines
- Answers are generated using large language models (LLMs)
Advances in BERT, neural networks, and embedding-based retrieval allow AI systems to understand intent instead of literal phrasing. Research from Google Research and OpenAI confirms that semantic search improves relevance for complex queries.
This shift transforms search engines into conversational research assistants.
Why real-time web data is critical for modern AI search
Static indexes struggle in fast-changing environments. Executives tracking financial data, engineers monitoring cloud incidents, or teams following AI research need real-time search, not cached results.
Real-time data matters because:
- Market conditions and APIs change rapidly
- AI research and tools evolve weekly
- Outdated data increases hallucinations
Perplexity retrieves live data at query time and pairs it with source tracking and citation systems. Industry insights from iPullRank and Bing show freshness is now a core relevance signal in generative AI search systems.
Core Architectural Layers Behind Perplexity’s AI Search
Perplexity’s system is a multi-layered architecture, not a single AI model. Each layer focuses on accuracy, relevance, and transparency.
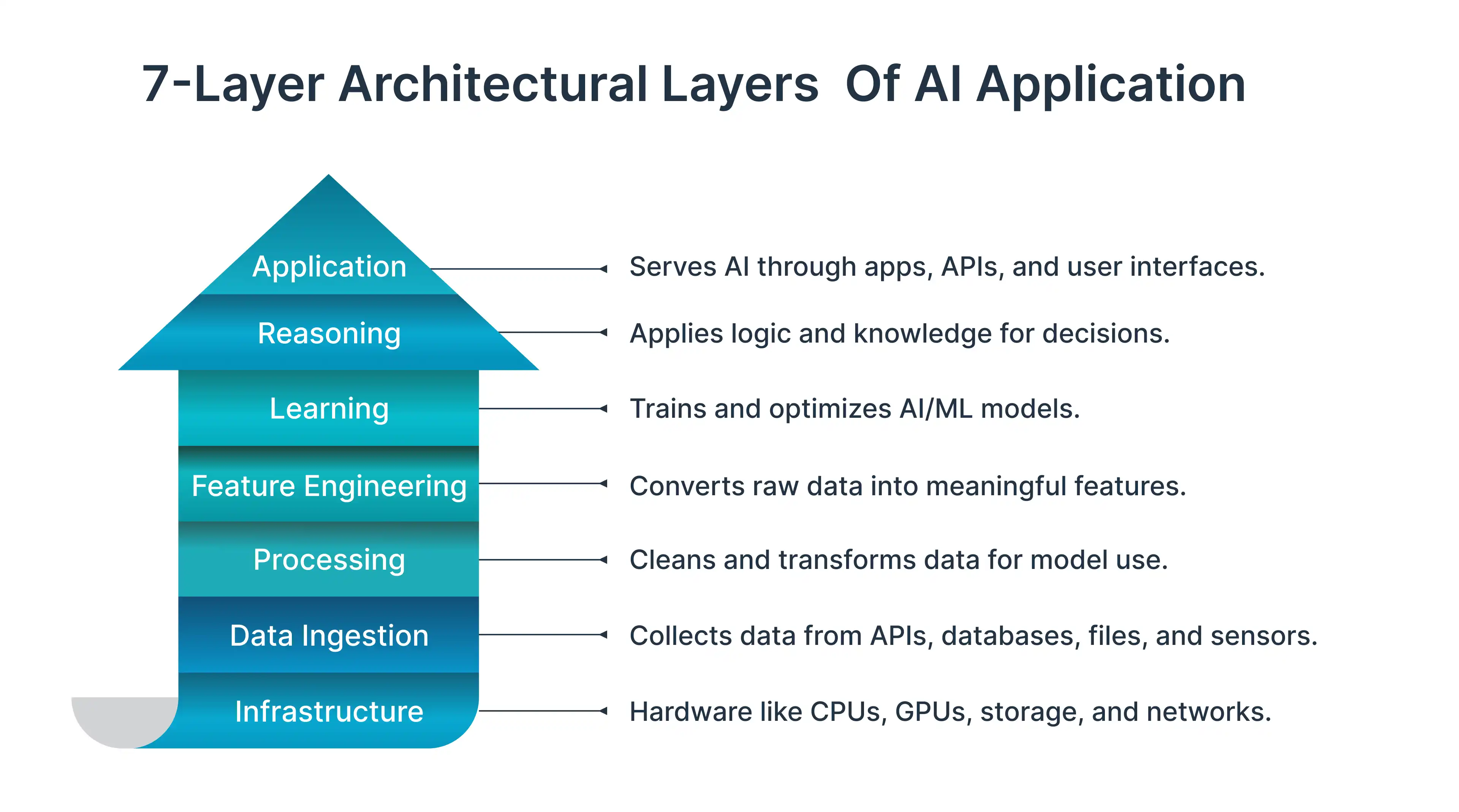
Real-time web crawling and data ingestion layer
Perplexity avoids dependence on static indexes by using on-demand crawling and API ingestion. This allows direct access to up-to-date content.
Key elements include:
- Lightweight crawlers for fresh web data
- API-based structured data ingestion
- Content filters and pasteurization layers
This approach reflects modern AI infrastructure practices discussed across Amazon Web Services and AI research platforms.
Retrieval-Augmented Generation (RAG) architecture design
Perplexity relies on Retrieval-Augmented Generation to ground answers in verified sources instead of memory alone.
RAG pipelines include:
- Hybrid retrieval using BM25 and vector embeddings
- Contextual reranking layers
- Chunking optimized for answer extractability
RAG is widely adopted across platforms built on Amazon Bedrock, Vespa AI, and vector databases, reducing hallucinations significantly.
Large language models used for answer generation
Perplexity orchestrates multiple frontier LLMs based on task needs:
- GPT-4, GPT-4o, GPT-3 from OpenAI
- Claude Sonnet, Claude Opus, Claude Opus 4 from Anthropic
- Open models like LLaMA 70B, Mixtral 8x7B, and Mistral 7B
Model routing optimizes latency, context length, and cost.
How Perplexity Processes and Ranks Live Web Data
Retrieving data is only part of the challenge. Ranking and validating it correctly is where AI search succeeds or fails. To achieve this, Perplexity relies heavily on vector search, a technique that represents queries and documents as numerical vectors based on semantic meaning rather than exact keywords.
Vector search allows the system to compare intent, context, and conceptual similarity across large volumes of live web data. Instead of matching terms literally, it identifies content that is meaningfully related to the user’s question. This makes vector search especially useful for long-form queries, ambiguous questions, and multi-turn conversational search, where traditional lexical search methods fall short.

Semantic understanding using embeddings and context mapping
Perplexity converts queries and documents into embedding vectors, enabling semantic similarity matching rather than exact keyword matching. This allows the system to understand meaning and intent instead of relying only on literal phrasing.
This enables:
- Better long-form question handling
- Context continuity across follow-ups
- Conversational search behavior
Embedding-based retrieval is now standard across AI-powered answer engines.
Source authority, freshness, and trust scoring mechanisms
Perplexity applies ranking models that evaluate:
- Domain authority
- Content freshness
- Cross-source agreement
This evolution mirrors how PageRank matured into trust-based ranking pipelines, critical for financial, medical, and enterprise use cases.
Handling conflicting, noisy, or incomplete real-time data
When sources conflict, Perplexity:
- Surfaces multiple viewpoints
- Flags uncertainty
- Improves future ranking via feedback loops and RLHF
This makes it suitable as an AI research tool, not just a chatbot.
Role of Citations and Transparency in AI Search Results
Citations are no longer an optional feature in AI search—they are the foundation of trust, accuracy, and adoption. As AI-powered answer engines move toward AI-First Discovery, users expect not just answers, but proof. LLM tracking tools help businesses monitor when and where their brand is cited across AI platforms, making it easier to measure AI visibility and strengthen their presence in AI-generated responses. This is especially critical in high-stakes domains such as financial data analysis, enterprise decision-making, and technical research, where hallucinations can have real-world consequences.
How Perplexity generates source-backed citations
Perplexity generates citations through a tightly coupled information retrieval and ranking pipeline, rather than post-processing answers after generation. The system retrieves content using hybrid retrieval pipelines, combining lexical methods with semantic indexing and vector embeddings, before passing context to LLMs.
Key mechanisms include:
- Entity linking across trusted domains and Knowledge Graph references
- A content understanding module that identifies answer-worthy passages
- Contextual reranking layers driven by Relevance Engineering
- Source attribution embedded directly into the answer generation step
This approach allows PerplexityBot and the Perplexity Assistant to cite sources inline, making verification instant. Architecturally, this reduces hallucinations and improves answer extractability—two major challenges in conversational AI.
Founder Aravind Srinivas has spoken publicly about building Perplexity as an “answer engine first,” where citations are inseparable from answers.
Importance of verifiable answers for user trust
Trust is the currency of AI adoption. Studies from the Nielsen Norman Group show that users—especially executives—are significantly more likely to rely on AI systems that provide visible citations and clear sourcing. This is amplified in environments where decisions are irreversible or costly.
Nielsen Norman Group study on AI trust and transparency
Verifiable answers matter because:
- They reduce perceived hallucinations in LLM outputs
- They support internal validation and auditability
- They improve confidence in conversational interfaces used by leaders
For CEOs and CTOs, AI systems without citations are risky black boxes. Citation-backed systems, on the other hand, behave more like AI research tools than chatbots—closer to how experts like Lex Fridman describe trustworthy human–AI collaboration.
Impact of citation-driven AI search on publishers and creators
Citation-driven AI search changes the incentive structure for content creation. Instead of rewarding volume or keyword density, systems like Perplexity prioritize clarity, authority, and semantic relevance.
Publishers and creators benefit when content offers:
- Original insights grounded in verifiable facts
- Clean structure optimized for conversational search engines
- High signal-to-noise ratio for content understanding modules
This shift encourages higher-quality content creation and discourages thin, SEO-only pages. For enterprises, it also enables better tracking through tools like Citation Tracker Spreadsheets, Rank Reports, and GEO testing frameworks.
Perplexity vs Google and ChatGPT: Architectural Differences
Although Perplexity, Google, and ChatGPT all operate in the search and AI space, their architectures reflect fundamentally different philosophies. Understanding these differences is critical for leaders deciding where to invest attention, integrations, or content strategy.
Perplexity positions itself as a conversational search engine, not a traditional search index or a general-purpose chatbot. This distinction drives everything from retrieval logic to user experience.
Index-based search versus answer-first AI search
Google’s architecture is built on search indexes, crawling at scale, and ranking algorithms like PageRank. Results are documents first, answers second.
Perplexity flips this model:
- The answer is the primary output
- Sources exist to validate, not replace, the answer
- Retrieval is optimized for answer synthesis, not page ranking
This answer-first model aligns better with modern workflows, where users want conclusions, not exploration. It also fits naturally into task automation, coding agents, and executive research use cases.
Differences between Perplexity and ChatGPT browsing mode
ChatGPT with browsing retrieves web pages as external context, but it remains generation-centric. Perplexity, by contrast, is search-native, with retrieval, ranking, and citation tightly integrated.
Key differences include:
- Built-in ranking pipelines vs ad-hoc browsing
- Persistent source citation vs optional references
- Research-oriented UX vs conversational assistance
This is why Perplexity is often preferred for code review, diff acceptance rate analysis, and technical comparisons, while ChatGPT excels at ideation and synthesis.
User experience and research workflow comparison
Perplexity’s UX is optimized for speed, verification, and synthesis. Users can quickly move from question to answer to source without context switching.
This makes it ideal for:
- CTOs evaluating infrastructure choices
- Engineers summarizing documentation
- Leaders conducting competitive or market research
In contrast, traditional search engines still favor discovery, while chatbots favor conversation. Perplexity sits in between—designed for focused, high-trust research.
Implications for SEO, GEO, and AI-Optimized Content
AI search fundamentally changes how content is discovered, ranked, and cited. For brands and enterprises, this requires a shift from classic SEO tactics toward Generative Engine Optimization (GEO).
How Generative Engine Optimization changes content strategy
GEO focuses on making content understandable, retrievable, and citable by AI systems. Unlike traditional SEO, which often relies on search engine ranking reports to track keyword positions, GEO optimizes for answer engines, not just search engines. It also focuses on tracking visibility across AI platforms like Perplexity, and tools such as SE Ranking now offer a Perplexity visibility tracker to help brands monitor how often and where they appear in AI-generated answers.Consequently, the availability of specialized answer engine optimization services now allows businesses to secure vital visibility across these evolving platforms.
Core GEO priorities include:
- Clear, direct answers to specific questions
- Strong source credibility and factual grounding
- Semantic structure aligned with conversational interfaces
This approach supports visibility across platforms like Bing Copilot, Google AI Mode, and Perplexity Assistant, where answers matter more than rankings.
Structuring content for AI retrieval and citation systems
AI systems prefer content that is easy to parse, segment, and reference. Poor structure directly reduces citation likelihood.
As AI-generated content becomes more common, many teams also refine outputs with AI humanizer to ensure the final text remains natural, readable, and aligned with human intent while still being optimized for retrieval systems.
Best practices include:
- Strong H2/H3 hierarchies with intent-driven headings
- Minimal filler and high answer density
- Explicit definitions and scoped explanations
This structure improves performance in AI-powered answer engines and supports better integration into Knowledge Graph–driven retrieval systems.
Preparing websites for real-time AI search engines
To succeed in real-time AI search, websites must support both technical and content-level readiness.
Key requirements include:
- Fast crawlability and clean information architecture
- Structured data compatible with AI retrieval
- Content designed for answer extractability
At Frugal Testing, we help teams validate this readiness using GEO testing, measurement frameworks, and AI Infrastructure Tool Index benchmarks, ensuring content performs well across modern generative AI search systems.
Conclusion: What Perplexity’s Architecture Signals for the Future of Search
Perplexity demonstrates that search is becoming answer-first, real-time, and trust-driven. AI-powered answer engines are reshaping how information is discovered, validated, and applied across enterprise workflows, research, and decision-making.
Based in India, Frugal Testing works with global teams to test, validate, and optimize systems for this new AI-first discovery era. As more organizations move toward building intelligent search, RAG pipelines, and production-grade AI systems, platforms offering specialized AI services- such as bnxt.ai - play a growing role in helping teams design, deploy, and scale these architectures. For CEOs, CTOs, and technology leaders, understanding AI search architecture is now a strategic necessity, not a technical curiosity.
People Also Ask
How does Perplexity AI access real-time web data?
Perplexity AI retrieves real-time web data using on-demand crawling and trusted API integrations instead of relying only on a static search index. This allows it to fetch the latest information at query time.
Is Perplexity AI more accurate than Google Search?
For research-focused queries, Perplexity often delivers clearer and more verifiable answers by summarizing information from multiple authoritative sources. Google Search remains stronger for broad discovery, while Perplexity excels at direct, citation-backed insights.
How does Perplexity AI select trusted sources?
Perplexity applies authority scoring, freshness signals, and cross-source validation to evaluate credibility. Sources that consistently provide reliable, up-to-date information are prioritized in answer generation.
What type of content performs best on AI search engines?
Content that is structured, factual, and citation-friendly performs best on AI search engines. Clear headings, concise explanations, and credible references improve visibility and answer extractability.
Can Perplexity AI be used for enterprise or financial research?
Yes, it is widely used for enterprise research, financial data analysis, technical comparisons, and decision support.






