

Artificial intelligence is transforming modern software engineering, but testing AI applications is far more complex than validating traditional software systems. Enterprise teams using Anthropic Claude AI models must deal with unpredictable outputs, hallucinations, evolving APIs, and prompt-sensitive behaviors that standard QA automation frameworks simply cannot handle.
For QA engineers, CTOs, and DevOps leads, the challenge is no longer just verifying whether an API endpoint returns a 200 response. Teams now need to evaluate language quality, reasoning consistency, safety, latency, and business accuracy across dynamic AI workflows. This is where structured Claude testing strategies become essential.
At Frugal Testing, enterprise QA teams are increasingly adopting AI-focused validation pipelines using tools like PromptFoo, DeepEval, LangSmith, and Ragas to improve AI application reliability. As AI agents, distributed agent orchestrators, and Model Context Protocol integrations become more common, organizations must completely rethink how testing fits into the AI development lifecycle.
Why Testing AI Applications Is Different from Traditional Software Testing
Traditional QA automation relies on deterministic logic. The same input should generate the same output every time. Claude AI and other large language models behave differently because outputs are probabilistic and context-driven. Understanding how does AI work at a fundamental level probabilistic reasoning over large context windows rather than rule-based logic is the first step to building a testing strategy that actually holds up.
Modern AI systems continuously interpret prompts, conversation history, tool integration results, and external knowledge bases before generating responses. This creates major testing challenges for enterprises building AI-powered software engineering assistants, generative AI tools, and AI-generated apps. Unlike traditional software testing services or automation testing services, validating AI outputs requires an entirely different evaluation mindset.
The Unique Challenges of Non-Deterministic Outputs, LLM Evaluation, and Enterprise AI Risk
Claude AI responses vary based on prompt phrasing, context length, temperature settings, and tool calls. A single API request can generate multiple acceptable responses, making traditional assertion-based testing ineffective.
Consider a DevOps chatbot using Claude Opus 4.7 that correctly answers infrastructure questions in one session, then hallucinates non-existent services like ‘AWS Strands’ in another session. This variability makes Claude AI output evaluation significantly harder than conventional software validation.
Enterprise AI risk compounds further when AI agents access sensitive systems such as:
- JIRA tickets and GitHub PRs.
- Database collections and critical API endpoints.
- Compliance systems and internal knowledge bases.
Incorrect outputs can directly introduce security issues including data exposure, unauthorized access, and compliance failures. According to the OWASP Top 10 for LLM Applications, prompt injection and insecure output handling are now among the most serious enterprise AI security issues teams must actively plan for.
Why Conventional QA Automation Breaks Down for Claude AI and Generative AI at Scale
Traditional automation frameworks like Selenium or Cypress validate fixed workflows. Generative AI applications, however, involve dynamic reasoning paths and variable responses that cannot be hardcoded into static assertions.
Teams building AI agents with the Claude Agents SDK often discover that even small prompt engineering changes can alter downstream outputs dramatically. Prompt engineering is therefore not just a development discipline but a core testing responsibility, covering:
- System prompt structure and role definitions.
- Output constraints and format requirements.
- Few-shot example design and context management.
This is especially visible in Claude Code workflows, where a single prompt adjustment can change how the model generates code, structures API calls, or handles edge cases entirely. To address this, organizations now use semantic evaluation frameworks, model-graded scoring systems, and LLM-based test case generation strategies that evaluate meaning, accuracy, relevance, and consistency across thousands of AI interactions.
Understanding Claude AI as a Testing Target
Claude AI models are increasingly used for enterprise automation, AI software development support, and product management workflows. Understanding how these models behave is essential before implementing any testing framework.
How Claude AI Models Work: Context, Output Variability, and Enterprise-Grade Reliability
Claude AI processes user prompts using transformer-based reasoning architectures capable of handling extremely large context windows. This allows AI applications to simultaneously analyze Slack threads, GitHub repositories, knowledge bases, and product specifications in a single reasoning pass.
Context-heavy reasoning also introduces output variability. Claude may prioritize different sections of a prompt across sessions, especially in long-running AI development testing pipelines involving Claude Code or multi-step agent workflows. For enterprises, reliability depends heavily on:
- Prompt design clarity and structure.
- Constrained tool access and output formatting.
- Structured prompt engineering pipelines and master prompt architectures.
According to Anthropic's documentation, prompt clarity and constrained tool access significantly improve consistency across production deployments.
Claude Sonnet 4.5 vs Claude Opus 4.7: Testing Considerations and Performance Metrics Across Variants
When comparing Claude Sonnet 4.5 vs Claude Opus 4.7, testing requirements differ substantially:
- Claude Sonnet 4.5 prioritizes speed and lower latency, making it ideal for customer support automation and real-time AI agents. For teams evaluating Claude as a ChatGPT alternative, Sonnet's throughput performance is a key differentiator worth benchmarking.
- Claude Opus 4.7 focuses on deeper reasoning and complex software engineering tasks, preferred for Claude Code workflows and distributed agent orchestrator systems requiring multi-step precision.
The release of Claude Opus 4.7 has raised the bar further, offering stronger reasoning capabilities that require QA teams to update their benchmark baselines and evaluation criteria with each new version. QA engineers must therefore benchmark multiple evaluation metrics across variants, including:
- Latency under concurrent workloads.
- Hallucination frequency and severity.
- Multi-turn memory retention.
- Tool integration reliability.
- API failure recovery rates.
These metrics help teams select the appropriate model for specific enterprise AI use cases and ensure testing coverage reflects real production conditions.
Key Evaluation Metrics: Accuracy, Hallucination Rate, Latency, and Consistency Scoring
Claude AI accuracy testing requires more than measuring factual correctness. Teams must evaluate contextual accuracy, reasoning quality, and operational reliability together as a unified measurement across every deployment stage.
Modern frameworks track:
- Hallucination scoring and semantic similarity evaluation.
- Toxicity detection and latency monitoring.
- Consistency scoring across repeated prompts.
Frugal Testing recently implemented automated Claude AI testing pipelines for a fintech client where repeated evaluation runs identified unstable responses during high-volume API bursts. By adding synthetic test data, semantic evaluation scoring, and prompt versioning controls, the team reduced output inconsistency by nearly 48% and lowered false-positive hallucination alerts by 35% during the first deployment cycle. The improvements significantly increased production reliability across high-volume enterprise workflows.
Core Challenges in Testing Claude-Powered Applications
AI applications introduce testing scenarios that continuously evolve as models update and enterprise workflows grow more complex. Three challenges consistently surface across organizations building on Claude.
Hallucinations, Prompt Sensitivity, and Output Inconsistency: Detection Strategies Using PromptFoo and LangSmith
One of the most critical Claude AI hallucination issues involves confidently incorrect outputs. These become especially dangerous when AI systems generate compliance recommendations, infrastructure commands, or Claude Code outputs that contain fabricated function calls or incorrect API structures without flagging any uncertainty.
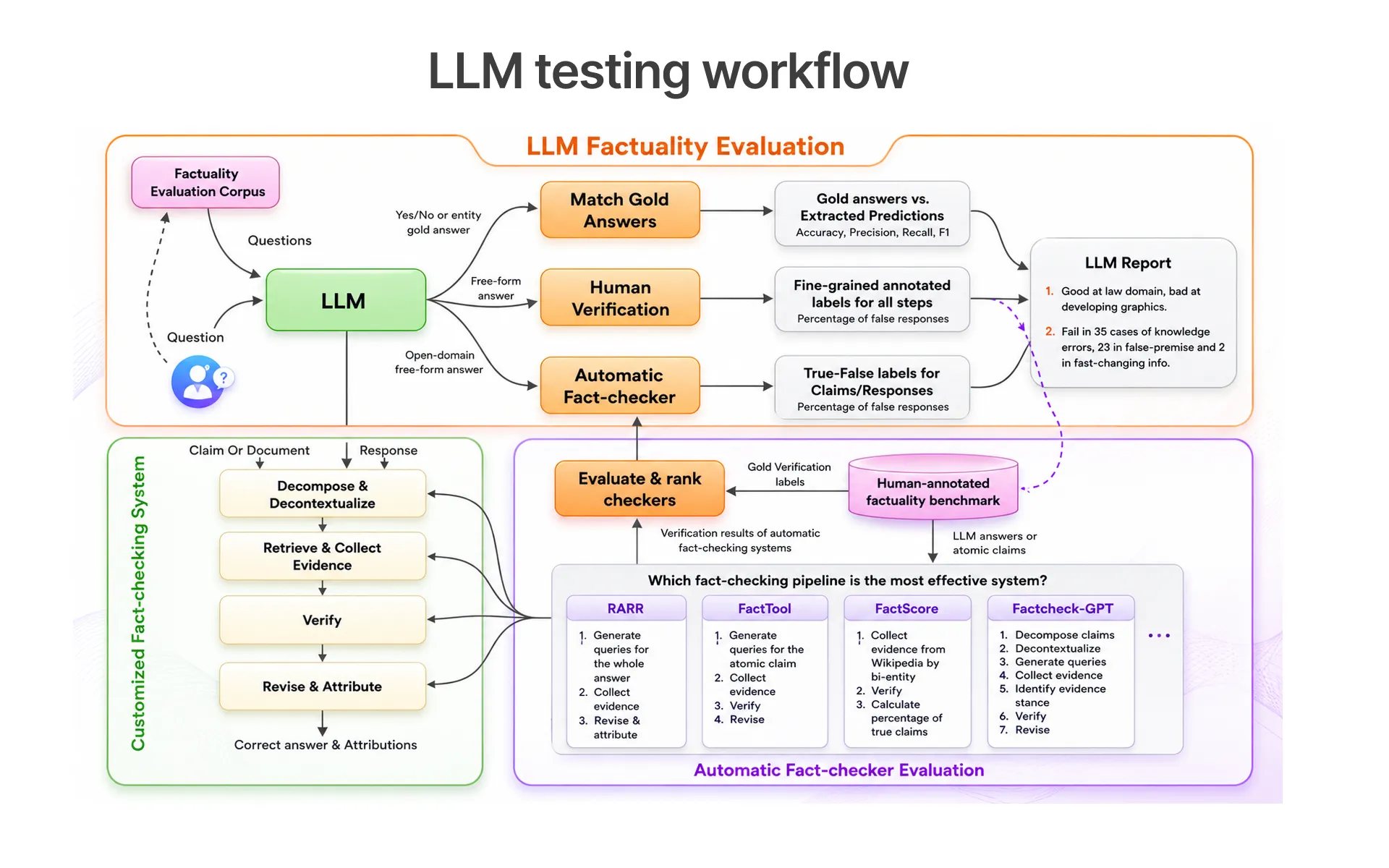
Tools like PromptFoo and LangSmith help teams:
- Compare responses across prompt variations systematically.
- Evaluate prompt sensitivity and measure output drift.
- Identify inconsistent behaviors before they reach production.
Teams testing Gemini 1.5 Pro integrations alongside Claude models often run benchmark suites that evaluate identical prompts across both providers, enabling better cross-model reliability comparison and helping identify gaps before deployment. Claude vs ChatGPT benchmarking is another common exercise, where teams validate whether Claude holds a consistent accuracy advantage on domain-specific tasks before committing to it as their primary AI technology. Prompt sensitivity testing also validates how small wording changes impact business-critical outputs, making it one of the most important Claude prompt testing techniques in enterprise AI governance today.
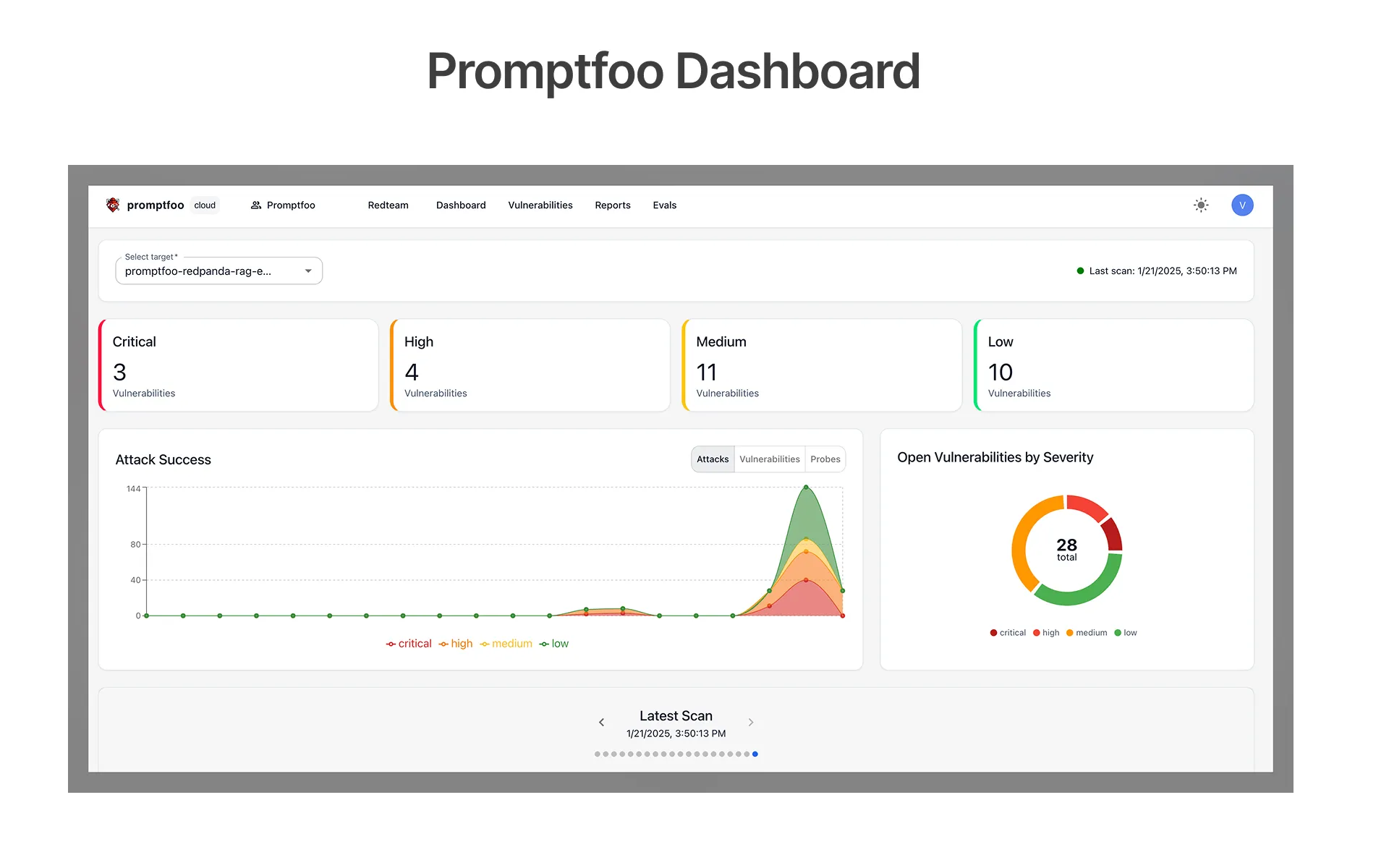
Regression Testing When Claude API Models Update: Versioning Prompts and Managing Synthetic Test Data
Anthropic continuously ships model releases and optimizations across its model family. While these updates improve capabilities, they can also break existing AI workflows unexpectedly, making regression testing a non-negotiable part of any enterprise QA strategy.
Teams should maintain:
- Prompt versioning repositories with change history
- Synthetic test datasets covering edge cases
- Historical benchmark outputs for cross-release comparison
This is especially critical for Claude Code pipelines that automatically generate GitHub PRs, write configuration files, or update database collections. A subtle reasoning change in a new model release could introduce serious software engineering defects that only surface in production. Many organizations now maintain dedicated AI release validation pipelines modeled on conventional CI/CD workflows, automatically evaluating prompts against expected semantic behaviors whenever new Claude API model versions ship.
Evaluating Multi-Turn Conversations, Stateful Workflows, and Enterprise Edge Cases
Unlike static applications, AI systems often operate as persistent conversational agents. Multi-turn memory introduces additional testing complexity because outputs depend heavily on prior interactions within a session, and errors in early turns compound through later responses.
Consider a customer support AI agent handling billing escalation workflows. The system must maintain accurate context across multiple prompts while respecting enterprise compliance rules and avoiding data leakage, both of which represent active security issues if left unvalidated.
QA teams therefore simulate:
- Long conversational chains and stateful workflow transitions.
- Edge-case prompt injections and incomplete user instructions.
- Tool failure recovery scenarios and compliance boundary testing.
These evaluations are critical for enterprise-grade Claude AI software testing deployments where a single session failure can have significant downstream operational consequences.
Frameworks and Tools for Testing Claude AI Applications
Modern AI testing requires specialized frameworks capable of evaluating semantic quality, operational safety, and enterprise compliance simultaneously rather than addressing each concern in isolation.
LLM Testing Frameworks Compared: PromptFoo, DeepEval, Ragas, and Model-Graded Evaluation
Several frameworks now anchor the AI QA ecosystem:
- PromptFoo handles prompt comparison and regression testing.
- DeepEval powers automated scoring pipelines.
- Ragas specializes in retrieval-augmented evaluation.
- LangSmith provides tracing and debugging for complex AI workflows including Claude Code execution traces and multi-agent tool calls.
These generative AI tools and AI QA automation tools are rapidly becoming standard across enterprise AI engineering teams in 2026. Model-graded evaluation is also growing quickly. Instead of human reviewers manually assessing outputs, a separate LLM evaluates response quality using predefined scoring criteria. Industry experts in LLM evaluation note that automated scoring dramatically improves scalability for large AI development programs, especially when thousands of prompt variations require consistent and objective assessment. Benchmarking Claude against competing models such as GPT-4o using these frameworks also gives enterprise teams a clearer picture of where each model excels and where additional testing investment is needed.
Prompt Versioning, Synthetic Test Data Generation, and Automated Test Coverage for Claude API
Effective Claude API integration strategies now include the following working together as a unified pipeline:
- Prompt repositories with version-controlled evaluations.
- Synthetic dataset generation for edge-case coverage.
- Automated scoring dashboards and API observability systems.
Teams often combine Claude API Python workflows with CI/CD automation to validate prompts continuously before production deployment. Securing an Anthropic API key and managing it correctly within environment configurations is the foundational first step teams often overlook when setting up automated testing claude AI pipelines for the first time. This is particularly important for Claude Code environments and AI coding tools where generated code goes directly into developer workflows and any output error can propagate rapidly through a codebase. For teams managing Claude API rate limits and monitoring Claude API error handling across high-volume deployments, this level of automated coverage is a fundamental requirement for responsible AI delivery.
Security, Safety, and Adversarial Testing: Red Teaming Claude-Powered Apps for Enterprise Compliance
Security testing has become mandatory for enterprise AI systems, particularly as Model Context Protocol integrations expose AI agents to a broader range of external tools and data sources. Red teaming exercises simulate malicious user behavior to surface security issues in AI reasoning before they reach production.
Active security issues in LLM applications include:
- Prompt injection attacks and unsafe tool calls.
- Sensitive data leakage and unauthorized API access.
- Toxic response generation and model manipulation.
These risks are amplified in Claude Code workflows and AI coding tools where the model has direct access to file systems, terminal commands, and code repositories. According to Anthropic's safety research, adversarial testing is critical for maintaining safe enterprise AI deployments. Organizations building experimental AI applications or deploying AI agents with Model Context Protocol integrations increasingly include dedicated security review cycles within their pipelines, treating adversarial testing with the same rigor as functional regression testing.
Practical QA Automation Strategies: Overcoming the Hardest Testing Challenges
AI testing success depends on combining automation, semantic evaluation, and human oversight in a cohesive strategy rather than treating each as a separate workstream operating independently.
How to Automate QA Testing with AI: Prompt Testing Pipelines and Output Evaluation at Scale
Enterprise teams now build scalable prompt evaluation pipelines integrated directly into CI/CD workflows. These systems automatically execute prompt suites, compare outputs, and generate evaluation scores after every deployment cycle.
Frugal Testing recently helped an enterprise software engineering team automate Claude API error handling validation across thousands of API requests, with the system monitoring rate limits, response latency, and hallucination behavior simultaneously, reducing manual review time significantly while improving overall deployment confidence. For organizations evaluating AI development services in USA or quality assurance testing providers, this kind of automated scoring pipeline is now the baseline expectation rather than an advanced feature.
Modern QA automation with LLMs includes:
- Continuous evaluation dashboards and automated benchmark reporting.
- Multi-model comparison testing and tool call verification.
- AI agent observability across distributed workflows.
Claude Code is increasingly integrated into these pipelines as both a subject of testing and an active participant, helping generate test cases, review prompt variations, and flag potential regressions before they reach staging environments. Teams looking to install Claude Code into their existing CI/CD infrastructure will find that it integrates cleanly with standard pipeline tooling, making it straightforward to add as both a testing subject and an evaluation assistant.
The Challenge of Measuring Claude AI Accuracy and How to Build Reliable Scoring Systems
One of the hardest problems in AI testing is measuring quality objectively. Unlike traditional applications, AI outputs often involve subjective reasoning where two correct answers may look entirely different in structure and phrasing, making binary pass/fail assertions insufficient on their own.
Reliable scoring systems combine:
- Human evaluation alongside semantic similarity scoring.
- Ground truth validation and task completion success rates.
- Consistency analysis across repeated test runs.
Anthropic research consistently emphasizes that AI evaluation requires layered scoring approaches rather than binary assertions. Organizations using Claude Code for automated development workflows increasingly rely on hybrid evaluation frameworks to determine production readiness with confidence rather than assumption.
Testing Best Practices Across the AI Development Lifecycle
AI testing should begin during prototyping rather than after deployment. Teams that wait until production to validate AI behavior consistently face higher remediation costs and greater operational risk than those who embed evaluation early and continuously.
From Prototyping to Production: Embedding Claude API Testing into CI/CD Workflows
Modern AI application development lifecycle strategies integrate testing at every phase:
- Prototype stage - prompt benchmarking and initial output validation.
- Integration stage - API integration testing and Claude Code output review.
- Staging stage - semantic regression testing and hallucination scoring.
- Production stage - continuous monitoring and real-time observability.
CI/CD pipelines now include automated prompt regression testing alongside traditional unit and integration tests. For teams using Claude Code in developer workflows, this means validating generated code outputs at every pipeline stage before they touch production repositories or live systems. Keeping prompt engineering practices version-controlled and peer-reviewed at each stage further reduces the risk of silent regressions introduced by wording changes that appear minor but affect model behavior significantly. Organizations building on Claude Code pricing models, particularly usage-based enterprise tiers, also benefit from optimization testing that identifies unnecessarily verbose prompts consuming excess tokens.
Enterprise AI Testing Governance: Team Roles, Review Cycles, and Continuous Evaluation
Successful enterprise AI programs require governance structures involving QA engineers, product management teams, DevOps leads, and AI specialists working under a shared accountability framework.
Organizations should establish:
- Prompt review cycles with defined ownership and sign-off processes.
- Security audit processes and model release validation checklists.
- Continuous performance monitoring systems that evolve alongside model updates.
Enterprises deploying Claude Agents SDK systems increasingly create dedicated AI governance committees to oversee tool integration permissions, monitor for active security issues across Claude Code and agent environments, and maintain operational safety boundaries. Teams deploying Claude Code and enterprise AI agents as part of a broader AI strategy also benefit from centralized governance that tracks evaluation metrics, prompt versioning history, and model release impacts across all workstreams. For companies seeking external AI development services or software testing services to complement in-house teams, governance documentation also accelerates vendor onboarding and compliance reviews significantly.
Conclusion: Building Reliable, Enterprise-Grade AI Applications with Claude
Testing AI systems requires a fundamentally different mindset from conventional software validation. Claude-powered applications introduce probabilistic outputs, evolving reasoning patterns, and operational security issues that traditional QA automation frameworks cannot fully address alone.
Key Takeaways: Challenges, Frameworks, and Metrics Every QA Team Needs
Successful Claude testing programs focus on:
- Semantic evaluation instead of exact output matching.
- Continuous regression validation after every model release.
- Hallucination detection and security-focused adversarial testing.
- Multi-turn workflow evaluation across stateful AI agents.
Whether teams are testing Claude Code pipelines, API integrations, or conversational AI agents, structured evaluation frameworks and disciplined prompt engineering practices are what separate reliable deployments from risky ones.
How a Structured Claude Testing Strategy Reduces Enterprise AI Risk and Improves Output Quality
Organizations that invest in structured testing frameworks deploy safer and more reliable AI applications. From Claude Code environments to enterprise AI agents, robust evaluation systems are now essential for scalable software engineering success. By combining strong governance, automated Claude AI testing pipelines, and modern evaluation frameworks like PromptFoo, DeepEval, LangSmith, and Ragas, Frugal Testing helps enterprises build trustworthy AI systems that operate confidently and consistently in production.
People Also Ask (FAQs)
Q1. How do you test Claude AI responses for accuracy and consistency in production?
Ans: Testing Claude AI responses for accuracy and consistency in production requires semantic scoring, hallucination detection via LangSmith, and automated prompt regression suites. Run consistency checks across repeated prompts after every model release to catch behavioral drift before it affects users.
Q2. What makes QA automation different when building Claude API-powered applications?
Ans: Claude outputs are probabilistic, not deterministic. Static assertion frameworks fail here. QA automation must use model-graded evaluation, semantic comparison, and LLM-based test case generation alongside disciplined prompt engineering to handle variable responses reliably.
Q3. Which frameworks work best for evaluating LLM-based test case generation with Claude?
Ans: PromptFoo and DeepEval are the strongest choices. For retrieval-augmented workflows, Ragas adds specialized faithfulness metrics. LangSmith provides trace-level visibility across Claude Code executions and multi-agent tool calls.
Q4. How do Claude AI hallucinations create security issues in software testing pipelines?
Ans: Hallucinations in Claude Code outputs can generate fabricated API calls, incorrect configurations, or flawed infrastructure commands that introduce real security issues when merged into production. Red teaming and adversarial prompt testing catch these before deployment.
Q5. How does testing Claude Sonnet 4.5 vs Claude Opus 4.7 differ across AI development lifecycle stages?
Ans: Claude Sonnet 4.5 testing focuses on speed, throughput, and real-time accuracy under load. Claude Opus 4.7 testing prioritizes reasoning depth, multi-turn coherence, and Claude Code reliability on complex tasks where output errors carry higher business or security risk, especially when benchmarked against competing models like GPT-4o.






