

TL;DR: Many SaaS teams will add their legacy QA process to Claude and ask why their tests continue to fail. This guide covers a 4-phase workflow: CLAUDE.md setup, agentic loops, a 3-tier grader, and production hardening, designed for teams that are shipping with AI.
Why LLM-Driven Development Demands a New Testing Approach
AI-generated code may have code that moves features faster, but it also introduces a new QA issue. The output could meet basic test conditions, but not under edge cases, race conditions, flaky prompted conditions, or varying model behaviors. This is why SaaS teams need to have testing workflows tailored to the Claude-assisted development environment.
Test-driven development is based on the premise that the output is deterministic write a test, write code to pass the test, repeat. Claude, Sonnet, and other agentic systems, however, will generate different outputs when they write code. A fast response in the day might become a slow response the next day.
Teams still following traditional TDD workflows are shipping faster but NOT safer SaaS applications.
- Deterministic statements are not valid for probabilistic outputs LLM outputs are context-dependent and not deterministic.
- Coverage is a tricky metric high coverage does not always mean high variance of the model, and test cases don't
- Fragile test gates slow down CI/CD pipelines and that is a problem
- Manual QA is not scalable the more agents you have, the more humans will be the limiting factor
This isn't the time to abandon structure. It's upgrading it, writing these AI SDLC-designed Claude workflows from scratch
Phase 1 Configuring the Blueprint via CLAUDE.md
Imagine that CLAUDE.md is the testing constitution for your repository. All Claude Code sessions utilize it, and everything you make here will impact all the tests that come downstream. Keep sentences short, simple, and eco-friendly.
Writing a Testing-Focused System Prompt for Your Repository
You should instruct Claude on your architecture, testing rules, and safety boundaries using your CLAUDE.md file. A vague system prompt generates generic tests that could apply to any project. A specific, stack-aware prompt generates tests that actually validate your codebase's architecture and constraints.
# CLAUDE.md -- Testing Configuration
## Stack
- Runtime: Node.js + TypeScript
- Framework: React (frontend), Express (API)
- Database: PostgreSQL via Prisma
- Payments: Stripe
- Testing: Jest (unit), Playwright (e2e)
## Testing Rules
- Never mutate production data. Use non-production databases only.
- Mock all Stripe API calls using stripe-mock
- Use factories, not fixtures, for PostgreSQL seed data
- All async tests must include timeout assertions
- Follow the deny array: [php artisan db:wipe, DROP TABLE, DELETE FROM]
## Test Command Contexts
- Unit: `jest --testPathPattern=unit`
- Integration: `jest --testPathPattern=integration`
- E2E: `playwright test`Defining Stack Rules, Mocking Data, and Test Command Contexts
Phase 2 Constructing the Agentic Testing Loop
After the configuration of CLAUDE.md, the agentic loop is started. Claude wakes up in your codebase, makes some post-feature tests, and iterates much like the observability layer and prompts that you build around it.
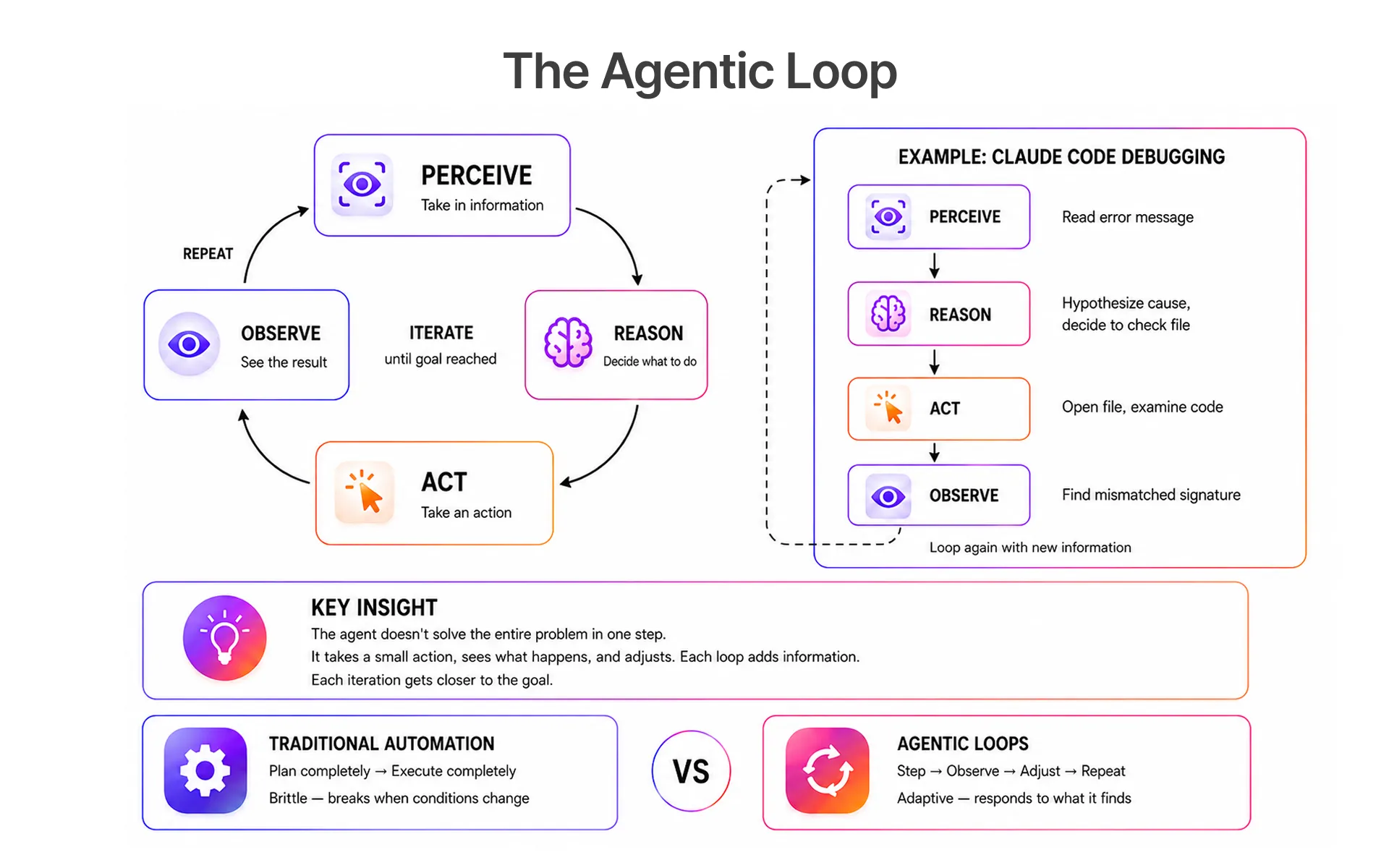
Prompting Claude to Generate Unit and Integration Tests Post-Feature
Here, prompt engineering is key. When a feature is sent to Claude, give them a context:
"You are allowed to access /src/payments/stripe-webhook.ts.
Generate Jest unit tests covering:
- Happy path: successful payment confirmation
- Edge case: duplicate webhook event
- Failure: malformed payload
Use stripe-mock for all Stripe API calls.
Output tests to /tests/unit/stripe-webhook.test.ts"This helps Claude reduce hallucinated imports and redundant coverage by providing a clear file target, scope boundaries, and edge case instructions.
How to Instruct Claude to Surface Edge Cases and Race Conditions
Any prompt you use will generate a generic test. For adversarial thinking, ask Claude some of the following questions:
- "What race conditions would you see if two users were to hit this endpoint at the same time?"
- "Write tests for the timeout cases on this WebFetch call."
- "So what if the PostgreSQL connection was lost while the transaction was running?"
But when you feed Claude your Jira ticket context or user stories, then its edge cases are near-dramatically more relevant.
Monitoring Test Loop Reliability with Structured Logging
When Claude is working on several files, silent failures accumulate quickly. Record each pass of the instrumented loop:
console.log(JSON.stringify({
phase: "test-generation",
file: targetFile,
testsGenerated: count,
status: "pass" | "fail",
timestamp: new Date().toISOString()
}));Failures will show up in your observability stack whether it's Google Analytics events, a Notion log, or a custom Kanban board before they make their way into your CI/CD pipeline.
Observability Patterns for Agentic Claude Test Pipelines
Three good patterns to use for production:
- Decision logs record all prompts that Claude was sent and the test file that Claude created
- Diff tracking do version-control tests separately, and then look at the differences before merging
- Failure tagging add a failure tag (model variance, async timeout, missing mock) to the flaky tests to spot trends over time
Phase 3 Implementing the 3-Tier Evaluation Framework
No one grader gets everything. The 3-tier framework merges deterministic checks, model-based judgment, and human calibration into one comprehensive evaluation system.
Tier 1 Deterministic Code Graders (Jest, PyTest, Playwright)
Your first line of defence. Jest is for TypeScript unit testing, PyTest is for Python services, and Playwright is for end-to-end user flows. These graders are fast, low-cost, and binary pass or fail, no interpretation needed.
Tier 2 Model-Based Graders (LLM-as-a-Judge Rubrics)
Where the quality of test output is relevant, not only to whether it ran, but to its quality, then a model is needed to evaluate a model. Set up an LLM-as-a-Judge rubric using Claude Opus or Sonnet as evaluator:
{
"rubric": {
"coverage_completeness": "Does the test cover the stated acceptance criteria?",
"edge_case_inclusion": "Are failure modes and race conditions tested?",
"mock_correctness": "Are external APIs (Stripe, Firebase) properly stubbed?",
"output_score": "1-5"
}
}Tier 3 Human-in-the-Loop Calibration for Senior Engineers
Tests whose Tier 2 scores exceed 3.5 automatically pass. Anything below triggers a senior engineer review. This gate identifies any misalignment with the product intent, despite passing the tests technically. Your VP of engineering decides the limit; Claude brings up the candidates.
Optimizing Claude Code Output for Faster Grader Execution
Slow graders put the brakes on developer momentum. Tune Claude Code output to reduce deeply nested describe blocks, redundant beforeEach setups, and scope imports. Together with automatic caching, decrease the latency of the API calls during multiple test generation runs in your CI/CD pipeline.
Real-World Example: In a Frugal Testing engagement, a B2B SaaS team running a Stripe-powered subscription platform implemented this 3-tier evaluation framework after Claude-generated integration tests passed Jest but failed in staging. After introducing an LLM-as-a-Judge rubric at Tier 2 with mock correctness scoring, the team reduced false positives in Stripe webhook tests by 60% within the first sprint. The improvement came not from adding more tests, but from applying smarter evaluation at the right stage of the pipeline.
Phase 4 Production Hardening and Environment Isolation
Sandboxing Data to Prevent Destructive Database Actions
Always point Claude toward a test database and never a production database. Apply this to CLAUDE.md explicitly with a denied array entry. Run standalone instances of PostgreSQL for each test, which are isolated, clean, and not subject to accidental db:wipe calls that have wiped more than one production environment.
Managing API State and Environment Variables Safely
Do not hardcode API keys, but store them in environment-specific .env files. Store Stripe API keys, Firebase credentials, and any MCP server tokens in a secrets manager. Send only the name of the variables not the values for Claude to pass:
STRIPE_KEY=$STRIPE_TEST_KEY # injected at runtime, never in CLAUDE.mdSetting Permission Boundaries and Read-Only Access Controls
Move Claude so that it can access only /src and /tests. No curl to any production endpoints, no wget from outside, no rclone syncing when testing. Your enforcement layer is the allow array in CLAUDE.md.
Building Reusable Test Templates with Claude
A workflow is not a system reusable templates are. Create a prompt template library that your team can pull from throughout the sprint instead of re-prompting from scratch each time.
Save templates in your knowledge base Notion, Google Drive, or a /prompts folder in your repo under version control.
Prompt Templates for Unit, Integration, and E2E Test Generation
Store templates in your knowledge base Notion, Google Drive, or a /prompts folder in your repo under version control.
Versioning Templates as Your Codebase Evolves
Tag prompt templates alongside code releases. When your Stripe integration upgrades or your PostgreSQL schemas change, outdated templates generate broken tests silently. A simple TEMPLATE_VERSION field in each prompt file and a quarterly review process keep your template library honest.
Integrating Claude Testing into Your CI/CD Pipeline
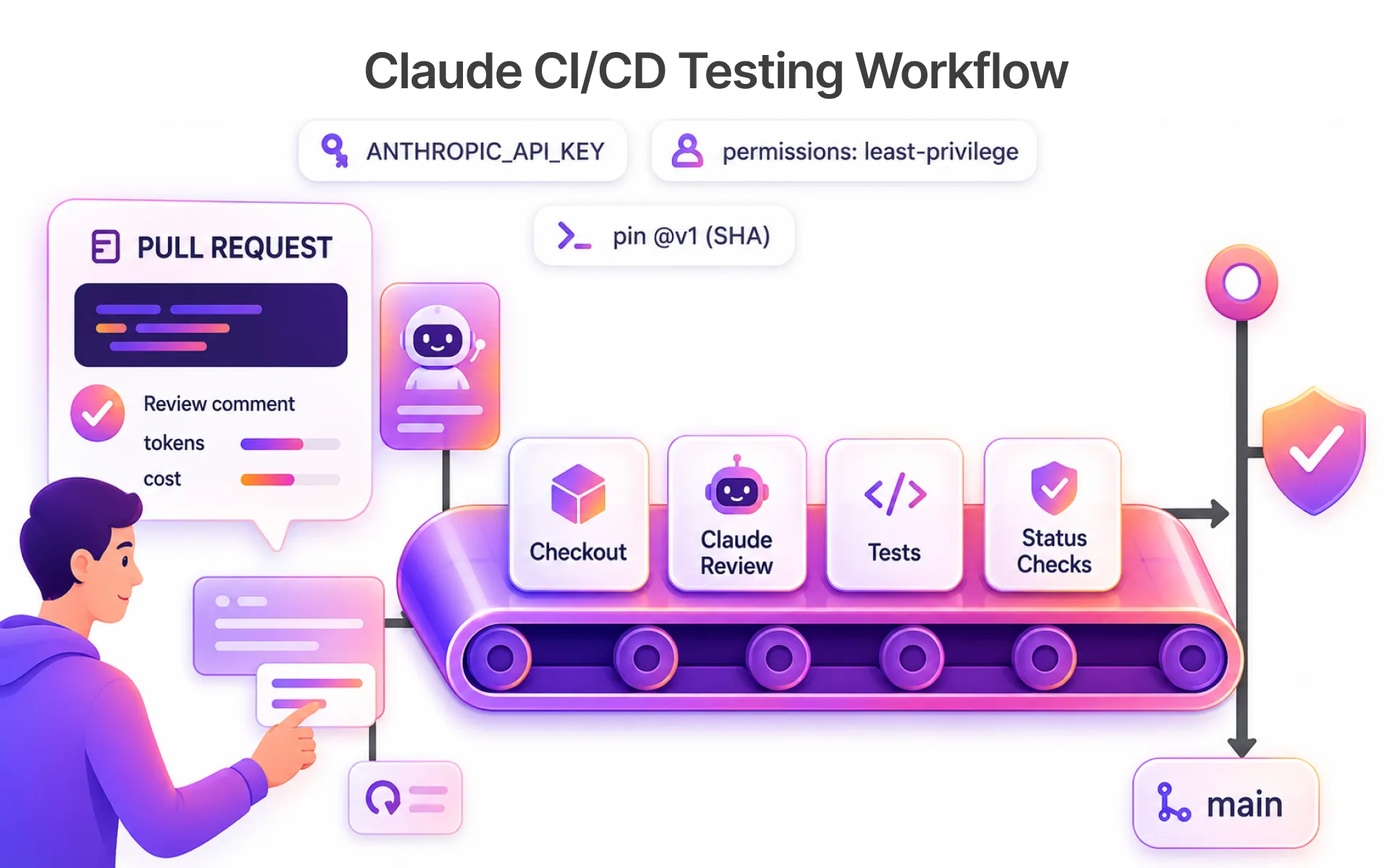
Wire Claude's agentic testing loop directly into GitHub Actions so test generation triggers automatically on every pull request. Define a workflow step that runs your CLAUDE.md-configured test commands, captures structured logs, and posts a summary to Slack or Microsoft Teams. Set pass/fail thresholds at the Tier 1 grader level only PRs clearing Jest, PyTest, and Playwright checks proceed to Tier 2 model evaluation. This keeps your pipeline fast for routine merges while reserving deeper Claude Code analysis for complex feature branches that touch core architecture.
Common Pitfalls and How to Avoid Them
Even well-configured Claude workflows break down in predictable ways. Catching these early saves weeks of debugging.
- Skipping the deny array one missing entry is all it takes for Claude to wipe a non-production database during a test run.
- Over-trusting Tier 1 pass rates high Jest coverage with weak assertions creates false confidence; always run Tier 2 on critical paths
- Prompt drift teams update code without updating CLAUDE.md, causing Claude to generate tests for the old architecture.
- No diff review gate merging Claude-generated tests without human diff review lets low-quality or redundant tests accumulate silently.
- Hardcoded API keys passing live Stripe or Firebase credentials into test prompts instead of environment variables is a security incident waiting to happen
Conclusion Shipping Bulletproof AI Pipelines Through Frugal Testing
Every phase in this guide exists to help your team spend testing effort where it actually catches real failures: a tight CLAUDE.md that stops bad tests before they generate, an agentic loop that logs what it does, a 3-tier grader that separates fast checks from deep evaluation, and a production environment locked down so Claude cannot cause damage.
In Frugal Testing's Claude workflow engagements, SaaS teams that committed to all four phases from CLAUDE.md configuration through to production hardening consistently reduced QA cycle times and shipped with fewer bug escapes than teams running ad hoc agentic loops without structured evaluation gates.
The teams pulling ahead in the AI SDLC are not the ones running the most tests they are the ones running the right tests, generated by well-prompted Claude workflows, reviewed at the right gates, and iterated on continuously. Start with Phase 1 this week. Get CLAUDE.md right, and the rest of the system compounds from there.
People Also Ask (FAQs)
Q1. How do you configure Claude to test microservices with shared state dependencies?
Ans: Isolate each microservice with its own sandboxed database instance and stub all inter-service calls using mock servers. Define service boundaries explicitly in CLAUDE.md so Claude generates tests scoped to one service at a time, avoiding cross-service state bleed.
Q2. How do you measure the ROI of switching to Claude-based testing workflows?
Ans: Track three metrics before and after: bug escape rate to production, average QA cycle time per sprint, and engineer hours spent writing tests manually. Teams typically report a significant reduction in manual test writing effort within the first 30 days of adopting Claude-based testing workflows.
Q3. How do you handle non-deterministic test failures caused by Claude output variance?
Ans: Tag flaky tests with a variance label, re-run them three times automatically, and only fail the pipeline if two of three runs fail. Feed the failure pattern back into your CLAUDE.md prompt as a constraint to reduce recurrence.
Q4. What is the safest way to pass database credentials to Claude in a sandboxed environment?
Ans: Never pass credentials directly in prompts. Inject them as runtime environment variables using your CI/CD secrets manager GitHub Actions secrets or AWS Serverless parameter store and reference only the variable name inside CLAUDE.md.
Q5. How do you fine-tune LLM-as-a-Judge rubrics to reduce false positives in Tier 2 grading?
Ans: Start with a calibration set of 20–30 manually reviewed tests scored by your senior engineers. Compare Claude Opus scores against human scores and adjust rubric weights until the delta is under 0.3 on a 5-point scale. Re-calibrate every quarter as your codebase evolves.






