

You’ve used it. Your team has used it. Maybe you’ve even integrated its API into your products. ChatGPT's ability to provide instant, human-like responses has marked a seismic shift in our digital world, demonstrating the power of modern generative models.
But have you ever stopped to ask: what kind of engine is powering this revolution in LLMs, Large Language Models? The answer lies in the ChatGPT infrastructure, a marvel of modern engineering designed to handle a scale previously thought unimaginable.
Handling billions of queries is not just a matter of having more servers. It requires a fundamentally different approach to computing, one that blends custom-built supercomputers, thousands of specialized processors, and a cloud architecture fine-tuned for artificial intelligence(AI). In this deep dive, we'll pull back the curtain on the hardware and software that make ChatGPT possible. More importantly, we'll show you how the principles behind its design can inform your own company's journey into scalable AI.
💡What’s Ahead?
📌 What Is ChatGPT's Infrastructure?
📌 How the Infrastructure Works: From Training to Inference
📌 The Core Components: A Partnership Forged in Silicon
📌 Blueprint for Success: Building Your Own AI Infrastructure
📌 Testing the Behemoth: Ensuring Reliability at Scale
📌 Common Pitfalls When Building for Scale & How to Avoid Them
What Is ChatGPT's Infrastructure?
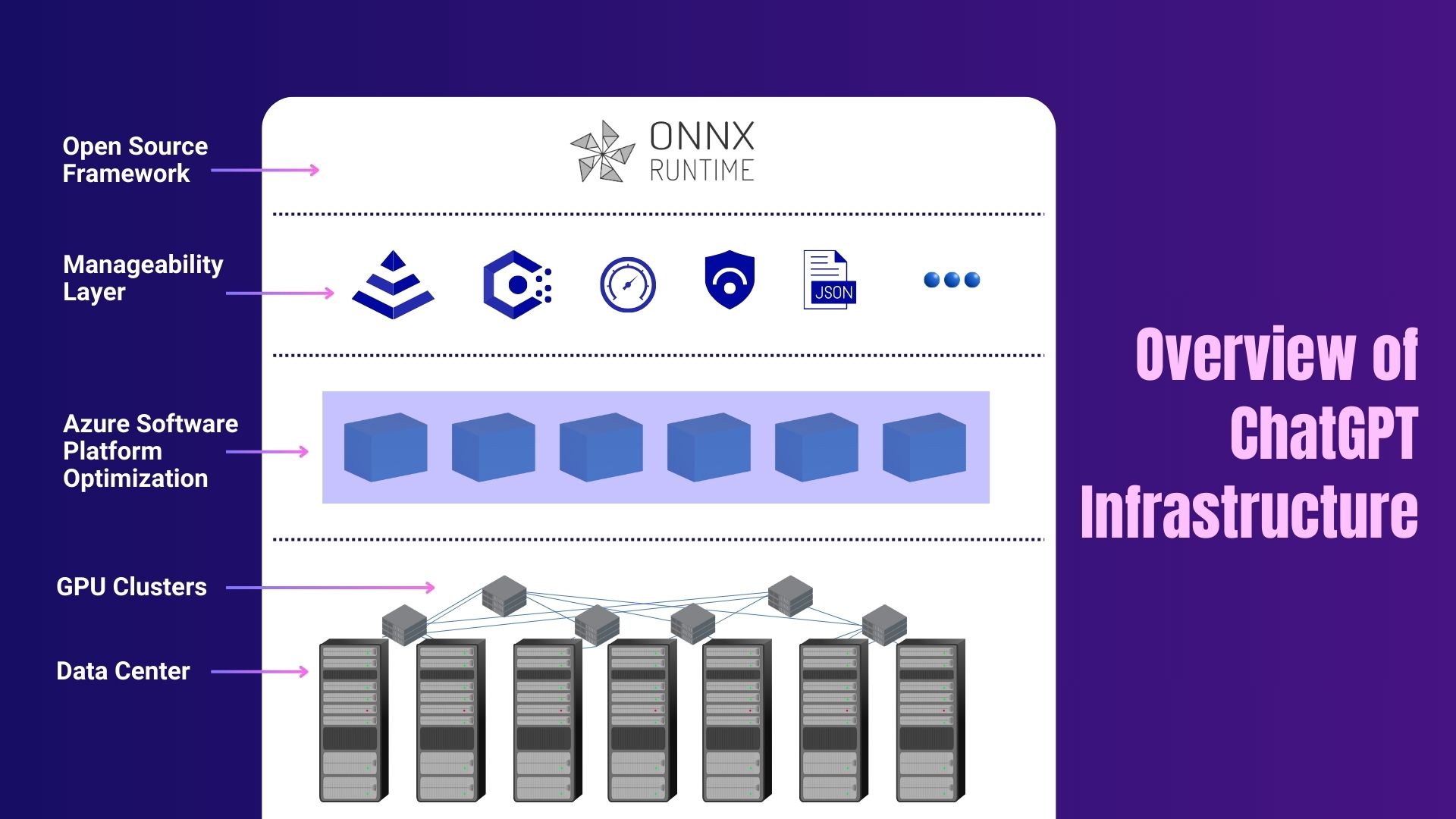
At its core, ChatGPT's infrastructure is a purpose-built supercomputing ecosystem, co-architected by OpenAI and Microsoft, and hosted entirely within the Microsoft Azure cloud. It's not a traditional set of servers in a few data centres; it's a massive, distributed system designed for a single purpose: to train and run gigantic Large Language Models efficiently.
According to Microsoft, this involves "tens of thousands" of powerful GPUs networked together to function as a single, cohesive unit (Source: Microsoft Official Blog, 2023). This setup, distributed across multiple Azure data centres globally, is one of the most powerful and sophisticated AI systems on the planet
💭 Why does this matter to your business today?
Because the challenges OpenAI solves are the same ones businesses face when deploying artificial intelligence at any significant scale: securing immense computational power, managing massive datasets, and delivering real-time performance. Content teams in this stack also run AI output through an AI detector before publishing. Output quality verification is part of that same challenge Proofademic is one resource teams reference when checking whether AI-generated content reads as human before deployment.
The Artificial Intelligence(AI) market is projected to reach US$244.22bn in 2025, and companies that master their AI infrastructure will be the ones to capture that value (Source: Statista, 2025). Understanding the blueprint behind ChatGPT provides a roadmap for building resilient, scalable, and cost-effective AI solutions. It shifts the conversation from "Can we use AI?" to "How do we build an infrastructure that supports our artificial intelligence ambitions for the next decade?"
💭 What is the core of ChatGPT's infrastructure?
The core of ChatGPT's infrastructure is a massive supercomputer built by Microsoft exclusively for OpenAI, hosted on the Azure cloud platform. It leverages tens of thousands of specialized NVIDIA GPUs for both model training and serving user queries (inference).
How the Infrastructure Works: From Training to Inference
The magic of ChatGPT isn't a single process but a tale of two vastly different workloads: training and inference. Each requires a unique architectural approach, and the infrastructure is designed to handle both seamlessly.

The Training Phase: Building the Brain
Training generative models like GPT-5, GPT-4 is an incredibly resource-intensive process that can take months. It involves feeding the model hundreds of terabytes of text and image data, creating immense learning opportunities for the model to understand patterns, grammar, and concepts. This process isn't fully autonomous; it requires significant human guidance through techniques like Reinforcement Learning from Human Feedback (RLHF).
- Massive Parallelism: To handle this, OpenAI uses a technique called parallel processing. The training job is broken into smaller pieces and distributed across thousands of GPUs. As noted by NVIDIA, their A100 and H100 GPUs are central to this process, designed specifically for the complex matrix operations at the heart of AI (Source: NVIDIA Blog, 2023).
- High-Speed Interconnects: The GPUs must communicate with each other constantly, sharing updates and synchronizing their learning. Standard networking would create a massive bottleneck. The system uses advanced networking technology like NVIDIA's NVLink and InfiniBand, which provides ultra-high bandwidth and low latency, allowing thousands of GPUs to act as one giant processor.
- Data Management: The model is trained on a colossal dataset. The infrastructure must be able to stream this data to the GPUs at an incredible speed to prevent them from sitting idle.
H3 - The Inference Phase: Answering the World's Questions
Once a Large Language Model is trained, it needs to be deployed to serve user queries. This is called inference, and the challenges are completely different. Instead of one massive, long-running job, the infrastructure must handle millions of small, independent requests simultaneously, each prompting the generative models to produce a unique response with near-instant latency. This is where techniques like chain of thought reasoning come into play, allowing the model to break down complex queries.
- Scalability and Orchestration: OpenAI uses container orchestration platforms like Kubernetes to manage the deployed models. This allows them to automatically scale the number of model instances up or down based on user traffic. If a million users log on at once, the system spins up more resources to handle the load without manual intervention.
- Model Optimization: The full-sized trained model is often too large and slow for real-time inference. Techniques like quantization (reducing the precision of the model's numbers) and pruning (removing unnecessary connections) are used to create smaller, faster versions that can answer queries with minimal latency.
- Global Distribution: To reduce lag for users around the world, the inference infrastructure is geographically distributed across various Azure regions. When you send a prompt, you're likely being routed to a model running in a data center closest to you.
H2 - The Core Components: A Partnership Forged in Silicon
ChatGPT's performance isn't the result of a single breakthrough but the integration of several cutting-edge technologies. The strategic partnership between OpenAI and Microsoft was the catalyst that brought these components together at an unprecedented scale.
- The Microsoft Azure Supercomputer: This isn't just a collection of servers; it's a bespoke system. Microsoft invested billions to build a dedicated AI computing platform for OpenAI. According to Microsoft's CTO Kevin Scott, the goal was to create a system that could train "increasingly large generative models" in a predictable and stable manner, something that had never been done before in the cloud. This provides the foundational layer of the physical space, power, cooling, and base-level networking.
- NVIDIA GPUs (A100 & H100 Tensor Core): These are the workhorses. Unlike general-purpose CPUs, GPUs are designed for parallel computation, making them thousands of times faster for AI workloads. Each H100 GPU, for example, contains specialized Tensor Cores designed to accelerate the mathematical operations used in deep learning. Tens of thousands of these chips form the computational heart of the system. This isn't a unique challenge for OpenAI; other massive generative models like Google Gemini or image-focused systems like Stable Diffusion rely on similar stacks of high-performance GPUs and networking.
- Quantum-2 InfiniBand Networking: This is the system's central nervous system. As reported by Dylan Patel of SemiAnalysis, high-speed networking is just as crucial as the processors themselves. InfiniBand allows all the GPUs to communicate with each other at extremely high speeds, which is essential for distributed training jobs where the model itself is too large to fit on a single device.
- A Tailored Software Stack: Hardware is only half the story. The entire system runs on a sophisticated software stack managed by Azure. This includes everything from the operating systems on the compute nodes to the Kubernetes platform that orchestrates the inference workloads. OpenAI and Microsoft have co-developed proprietary software to manage and monitor these massive training runs, ensuring they can recover from the inevitable hardware failures without losing weeks of progress.
📑 Mini Case Study: The Power of Partnership
In the early days, OpenAI trained its models on its own, smaller-scale infrastructure. However, their ambitions quickly outgrew their capabilities. The partnership with Microsoft in 2019 was a turning point.
Microsoft brought not only funding but also its deep expertise in building global-scale cloud infrastructure. This collaboration allowed OpenAI to focus on model research while Microsoft focused on building the "scaffolding" required to scale those models to sizes like GPT-4. This symbiotic relationship is a masterclass in how B2B partnerships can accelerate innovation.
H2 - Blueprint for Success: Building Your Own AI Infrastructure
You don't need a multi-billion-dollar budget to build effective artificial intelligence infrastructure. The principles that power ChatGPT can be scaled down and applied to your business. The key is to make smart architecture decisions that leverage the power of the cloud and focus on the right architectural patterns

1. Start with Cloud-Native AI Platforms
The first rule is not to build your own data center. Cloud providers have already made massive capital investments in hardware and networking. You should leverage managed AI platforms that abstract away the complexity.
- What to do: Start with services like Azure Machine Learning, Google Cloud AI Platform, or Amazon SageMaker. For teams starting out, platforms like Hugging Face offer pre-trained models that can be fine-tuned, allowing you to leverage powerful AI without training a model from scratch.
2. Choose the Right Compute for the Job
Not all AI tasks are created equal. Using the wrong type of processor is like using a sledgehammer to crack a nut-inefficient and expensive.
- What to do: Use GPUs (like NVIDIA's A100 or H100 series) for deep learning model training. For inference, you might use smaller GPUs or even specialized inference chips. For data processing and traditional machine learning, CPUs may be sufficient and more cost-effective.
3. Implement a Robust MLOps Strategy
MLOps (Machine Learning Operations) is the practice of applying DevOps principles to machine learning workflows. Integrating MLOps early in the development process is crucial for achieving scale and reliability.
- What to do: Use tools like Kubeflow, MLflow, or the MLOps features built into cloud AI platforms. Automate your workflows using infrastructure-as-code tools to define your environment in reusable code blocks. Think of it like a well-designed online store: the data pipeline is your inventory management, the model is the product, and the inference endpoint is the checkout feature. It must be fast, reliable, and handle every customer seamlessly. It's the final, critical step where value is delivered.
💭 Do we really need to understand all this hardware to use AI?
"Not at all. The beauty of cloud AI platforms is that they manage the hardware for you. Your focus should be on building a clean data pipeline and a solid MLOps workflow. You can start with a single managed GPU instance and scale up as your business needs grow, paying only for what you use."
Testing the Behemoth: Ensuring Reliability at Scale
An infrastructure of this magnitude, with tens of thousands of interdependent components, has an immense number of potential failure points. Testing isn't a final step; it's a continuous, multi-layered process designed to guarantee stability. Delivering a consistent and reliable user experience is a fundamental expectation, and rigorous testing is the only way to meet it at this scale.
- Hardware Burn-In: Individual components are stress-tested at maximum load to screen out faulty hardware before integration, preventing system-wide bottlenecks.
- System-Level Stress Testing: Automated code blocks simulate massive user loads to find bottlenecks and validate the model's AI reasoning under pressure.
- Chaos Engineering: Because scaling laws and power laws make failures a certainty at this scale, faults are intentionally injected to prove the system is truly fault-tolerant and can self-heal.
Common Pitfalls When Building for Scale & How to Avoid Them
Building AI infrastructure is a complex journey, and there are common traps that many businesses fall into. Awareness is the first step to avoidance.

Pitfall 1: Underestimating and Mismanaging Costs
The pay-as-you-go model of the cloud is a double-edged sword. A common mistake is a poorly configured process that might, for instance, continue generating outputs in a loop, racking up huge costs from unattended API calls.
- How can we manage the high cost of GPU instances?
Actively manage your cloud spending. Use cloud provider cost management tools to set budgets and alerts. Leverage spot instances' unused compute capacity offered at a significant discount for training jobs that can be interrupted. Most importantly, implement aggressive auto-scaling policies to automatically shut down resources when they are not in use.
Pitfall 2: The Data Bottleneck
Many teams invest heavily in GPUs only to find their training jobs are still painfully slow. Often, the problem isn't the compute; it's the data pipeline.
- Why is our model training so slow even with powerful GPUs?
Your GPUs are likely "starved" for data, meaning they are sitting idle waiting for the next batch of information to process. Your data storage and retrieval systems must be fast enough to keep up. Invest in high-performance cloud storage and optimize your data preprocessing code to be as efficient as possible. - Pro Tip: Always monitor your GPU utilization during training. If it's consistently below 80-90%, you almost certainly have a data input/output (I/O) bottleneck. Fix the data pipeline before buying more GPUs.
Pitfall 3: Ignoring Scalability from Day One
A model that works perfectly on a developer's laptop can fail spectacularly when faced with thousands of simultaneous users. A scalable architecture is not something you can add on later.
- Our model works on a single machine but fails under load. What's wrong?
Your application needs to be architected for distributed systems. Containerize your model and application using a tool like Docker. Then, use an orchestrator like Kubernetes to manage and automatically scale these containers across a cluster of machines. This is the industry-standard approach for building resilient, scalable artificial intelligence services. For more detailed guidance, check out our guide on architecting for scalability.
Why is QA Essential to Build a Scalable Infrastructure?
At a massive scale, infrastructure failures are inevitable. Continuous Quality Assurance (QA) is essential for the stability and reliability that users demand. Building an expert in-house QA team is slow and expensive, which is why software outsourcing offers a powerful strategic advantage:
- Specialized Expertise: Instantly access expert testers for performance, security, and AI validation without the cost of hiring.
- Reduced Costs: Convert high fixed salaries and tool expenses into a flexible, predictable operational budget.
- Objective Quality View: Get an unbiased assessment of your product to find critical issues your internal team might miss.
- Faster Launches: Accelerate your release cycle with parallel testing that gets your product to market quicker.
- On-Demand Scaling: Easily scale your testing efforts up or down to match project needs without hiring delays.
This is where a software testing company like Frugal Testing comes in. With over 100+ years of collective expertise, we provide the specialized partnership needed to ensure your AI infrastructure scales reliably.
Quick Recap
The infrastructure powering ChatGPT is a testament to what's possible when visionary AI research meets world-class cloud engineering. It's a complex, powerful, and purpose-built system that represents the pinnacle of modern computing.
While you may not be building the next GPT-4, the core principles remain the same: leverage the cloud, choose the right tools for the job, automate through MLOps, and design for scale from the very beginning. The journey to powerful generative models is an architectural one, and getting the foundation right, from ethics to infrastructur,e is the most critical step.
People Also Ask
👉 How does ChatGPT understand and generate human-like responses?
ChatGPT has been trained on a wide range of conversations and information, so it recognizes patterns in language. When you ask something, it predicts the most natural response, making it feel like you’re chatting with a real person.
👉 How to use ChatGPT for QA Testing?
You can use ChatGPT to quickly generate test cases, scenarios, and edge conditions from requirements or user stories. It also helps validate APIs, write automation scripts, and explain complex QA concepts in simple terms.
👉 How does ChatGPT make money?
ChatGPT makes money through paid subscriptions like ChatGPT Plus and enterprise plans. It’s also monetized via API access that businesses integrate into their own apps and services.
👉 Is Perplexity AI better than ChatGPT?
Perplexity AI is stronger for fact-checked, real-time answers with citations. ChatGPT is better for natural conversations, creativity, and versatile use cases.






