

On 12 June 2026, Anthropic switched off two of the most capable AI models ever released, three days after launching them. Not a bug. A US government export control directive, citing national security. Two weeks later, OpenAI shipped GPT-5.6 only to a short list of government-approved partners. The pattern: security testing, not raw capability, is now the release gate for frontier AI, and it started with Anthropic's Claude Mythos Preview. Most enterprises still treat capability as the finish line. These two cases show it has moved. Here is what happened, why AI agents capable of autonomous exploit development triggered it, and what the same scrutiny means for any team shipping LLMs into production.
The Timeline: What Actually Happened to Mythos 5 and GPT-5.6
Why Anthropic Pulled Fable 5 and Mythos 5
Anthropic had no reliable way to segment users by nationality in real time, so it disabled both models for every customer worldwide. The reported trigger was a jailbreak that bypassed Fable 5's guardrails and exposed the underlying Mythos architecture's cyber capabilities, including autonomous vulnerability discovery. Anthropic's own red-team reporting on Claude Mythos Preview is stark: the model independently weaponised a seventeen-year-old remote code execution flaw in FreeBSD, chaining stack and heap overflows into a working zero-day exploit with no human guidance, and produced 181 working browser exploits where the prior generation managed two. That is the AI-written zero-day exploit that turns a chatbot release into a national security conversation. The Commerce Department lifted the restrictions on 1 July 2026, after a nineteen-day suspension.
Why OpenAI Staggered the GPT-5.6 Rollout
OpenAI took the lesson. When it announced GPT-5.6 (Sol, Terra, and Luna) on 26 June, access went only to partners approved under a Trusted Access for Cyber-style vetting process, reviewed customer by customer, after officials judged its cyber capability on par with Mythos Preview on OpenAI's own cyberattack benchmark, ExploitBench. GPT-5.6 Sol also posted strong results on GeneBench v1, a biology benchmark, a reminder that agentic coding gains show up across domains. The Silicon Valley rivalry between the two labs is now shaping policy as much as product. Check the latest coverage before quoting current status.
Why Security Testing, Not Benchmarks, Is the New Release Gate
Frontier launches used to be gated by internal safety evaluations: harmful content checks, bias testing, refusal behaviour. June 2026 added a harder gate: cyber-offensive capability review, formalised in OpenAI's Preparedness Framework and Anthropic's own scaling commitments. Regulators now ask whether a model can independently develop exploits and build attack chains against production systems.
The contrarian bit: the delay is not a failure of engineering. Shipping AI agents capable of autonomous vulnerability discovery without independent security testing is the failure. The gate is working as designed, and it will not stop at Mythos 5 or whatever ships in Anthropic's Un-0 model series next.
What Is Red Teaming in an AI Context
Red teaming means attacking your own system the way a motivated adversary would, before a real one does. AI red teaming targets the model itself: adversarial prompts, universal jailbreaks, data extraction, and agentic tool misuse. That makes LLM red teaming different from conventional application security testing. Static application security testing scans code for known flaw patterns; it cannot tell you whether a model will reverse engineer a binary and produce exploit code on request. Binary reverse engineering used to require a specialist. Mythos Preview does it as a workflow.

LLM Security Risks and the Palo Alto Networks Test Case
The LLM security risks regulators watch are specific: autonomous exploit chaining, jailbreak-assisted vulnerability research, and agents misusing their tools. Palo Alto Networks published a defender's guide crediting AI-assisted discovery for dozens of findings across its own products, including flaws touching a Default Servlet component, shipped as new Threat Prevention signatures. Independent researchers disputed how much credit belonged to AI versus routine static analysis: without independent LLM evaluation metrics like jailbreak resistance rate and prompt injection success rate, vendor claims about AI-found bugs are unverifiable either way.
The Governance Frameworks Behind the Scrutiny
The NIST AI Risk Management Framework organises this work into four functions: Govern, Map, Measure, and Manage. Security testing sits mostly inside Measure, but cyber evaluations only work when the other three feed it: a documented model inventory and clear ownership of risk.
The recent White House executive order on pre-release federal review adds enforcement NIST never had, effectively building an export control list for frontier capability by another name. AI policy is also splitting by geography: the EU AI Act's high-risk classification requirements create a second compliance track, and data sovereignty rules increasingly shape which models a regulated company can deploy, pushing procurement toward model agnosticism, architecture that does not assume any one vendor's model will stay available.
What This Means If You Are Deploying AI, Not Building It
You are probably not releasing a frontier model. You are deploying LLMs into products and agentic coding tools, where the exposure lives: third-party model risk, prompt injection, data leakage, and shadow AI nobody inventoried. Vulnerability economics matter too. AI is compressing the cost of finding a bug toward zero while patch governance still moves on a monthly cycle, and that gap is where breaches happen.
Getting ahead of it starts with a model inventory, risk classification per use case, a defined LLM evaluation framework with regular cyber evaluations, and alert triage built into incident response. Most of this maps onto security programs your team already runs for conventional software, applied here with real threat intelligence to systems that talk back.
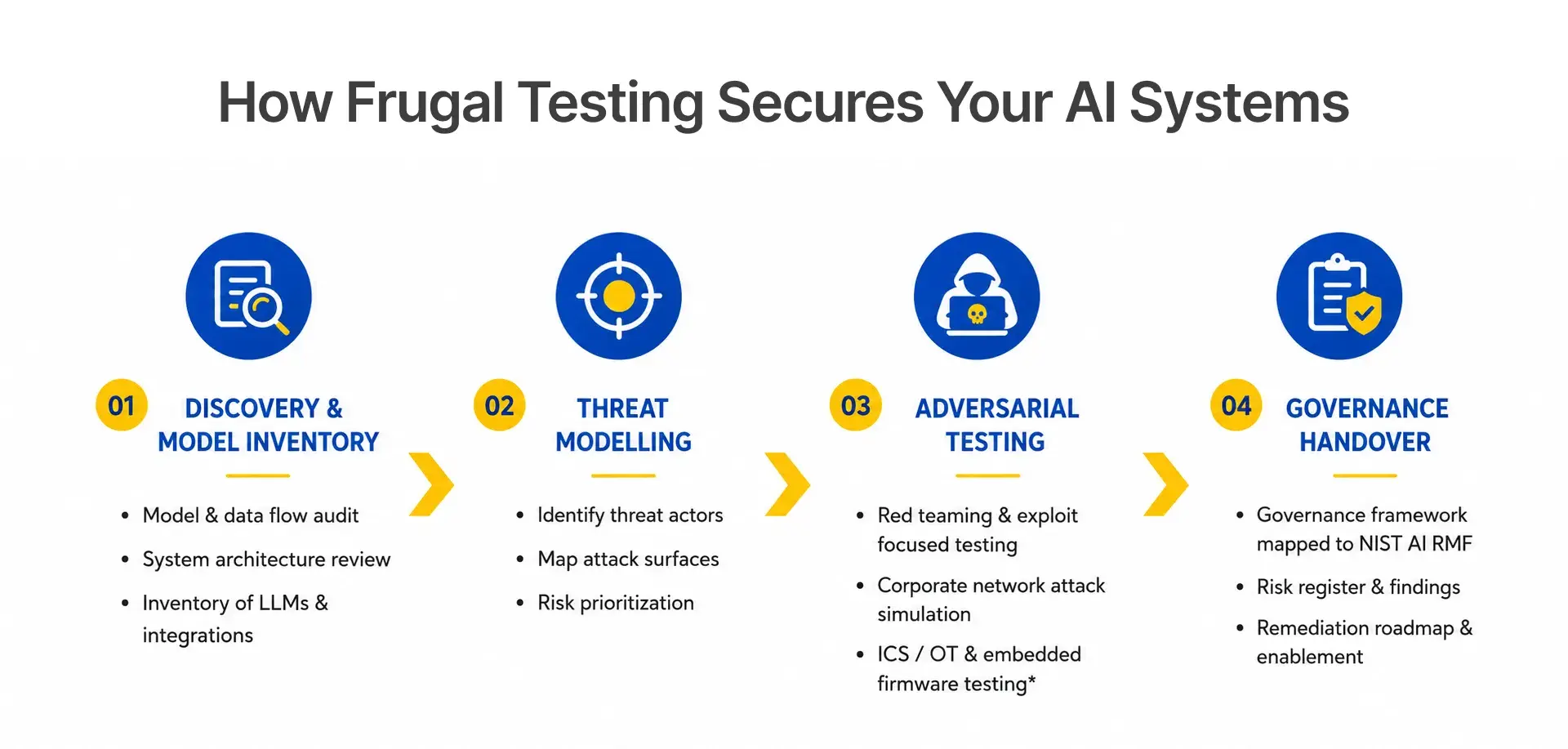
How Frugal Testing Helps You Build AI Systems That Pass Scrutiny
Frugal Testing provides independent AI red teaming, LLM security testing, and governance implementation mapped to NIST AI RMF. The engagement runs in four steps: discovery and model inventory, threat modelling, adversarial testing including a corporate network attack simulation where relevant, and governance handover. Week one covers the model and data flow audit. Weeks two and three are red teaming and exploit-focused testing, extending into industrial control system and embedded firmware contexts for operational technology clients. Week four delivers the governance framework and remediation plan.
The most common finding is the same across engagements: injection paths through user-supplied content that internal testing never exercised, caught and closed before launch. We also run cyber range exercises so teams can see how an LLM-integrated system holds up under a live attack chain, not just a checklist. At close, you own a tested model, a documented risk register, and software resilience your team can maintain independently, building on the same AI model testing discipline we apply across QA engagements.
If your team has LLMs in production, is evaluating a frontier model, or is staring at an AI vendor questionnaire with no good answers, we should talk.
"The delay is not the failure. Shipping a model that can find exploits, without testing it as an adversary would, is the failure."
Key Takeaways
- Security testing is now the release gate for frontier AI. Capability gets a model built; security review gets it shipped.
- Claude Mythos Preview's red-team findings, autonomous exploit chains, and 181 working browser exploits show why regulators moved fast.
- AI red teaming targets model behaviour, not code, and needs its own metrics.
- NIST AI RMF, the EU AI Act, and emerging AI policy give deploying teams a way to get ahead of scrutiny.
- Start with the basics: model inventory, risk classification, patch governance, alert triage.
The Gate Is Moving Down the Stack
June 2026 will be remembered as the month security testing stopped being an internal checkbox and became a release condition enforced from outside. Frontier labs felt it first because they are most visible. But procurement teams, insurers, and regulators read the same headlines, and the questions they ask of ordinary AI deployments are already sharpening. Teams that treat this month as someone else's problem will answer those questions under pressure. Teams that start testing now answer them on their own terms. Which one describes yours?
People Also Ask (FAQs)
Q1. What is red teaming in AI, and how is it different from traditional security testing?
Ans: AI red teaming attacks model behaviour through adversarial prompts and tool misuse, not code. Traditional security testing scans for known flaw patterns; it cannot evaluate a probabilistic system.
Q2. Why did the US government delay Claude Mythos 5 and GPT-5.6?
Ans: Both were flagged for advanced cyber capability. Anthropic's models were suspended under an export control directive and restored on 1 July 2026; GPT-5.6 launched to government-approved partners only.
Q3. What is the NIST AI Risk Management Framework?
Ans: A voluntary US framework organising AI risk work into four functions: Govern, Map, Measure, and Manage. Security testing sits primarily within Measure.
Q4. Do smaller companies need AI red teaming, or just frontier labs?
Ans: Yes, scaled to risk. Any production LLM deployment carries prompt injection and data leakage exposure, regardless of size.
Q5. What are common LLM evaluation metrics used in security testing?
Ans: Jailbreak resistance rate, prompt injection success rate, and vulnerability discovery containment. Track them per release, not once.



.webp)
