

In API testing engagements, the most common gap is not tool availability but a lack of a risk-based approach for assessing coverage relative to the business value of APIs. Many have Postman, REST Assured, and a dozen more, but they're unclear about the most important APIs to test if something goes wrong.
This post works through that problem, covering testing priorities, test design, automation, security, monitoring, and provides 7 actionable practices you can use.
Introduction: Why Business Risk Must Drive Your API Strategy
An API testing strategy describes what to test, how to test, and to what depth. Typically, this covers functional, security, performance, and integration testing on your API layer.
But if testing doesn’t happen under the context of business risk, then effort is distributed evenly, and the same level of energy will go towards testing a reporting endpoint as will go towards testing your payment processing API.
This is why gaps are formed in critical areas that you absolutely cannot afford to ignore.
Think about what each of your APIs actually does inside your company: payment processing, authentication, data synchronization to compliance systems, etc. If there’s a failure in these areas, it’s more than a technical annoyance. It’s a financial hit, a damage to trust, and a compliance violation.
When you build the API testing strategy around the business risks of APIs, you’ll start moving away from testing by quantity to testing by failure impact.
A Step-by-Step Framework for Risk-Based API Testing
Map APIs to Critical Business Workflows
Your API documentation is likely to include a list of endpoints. However, it’s unlikely to tell you which are most important when something fails.
Begin by selecting key workflows such as those impacting revenue, customer experience, or business continuity, checkout, authentication, order fulfillment, and data sync.
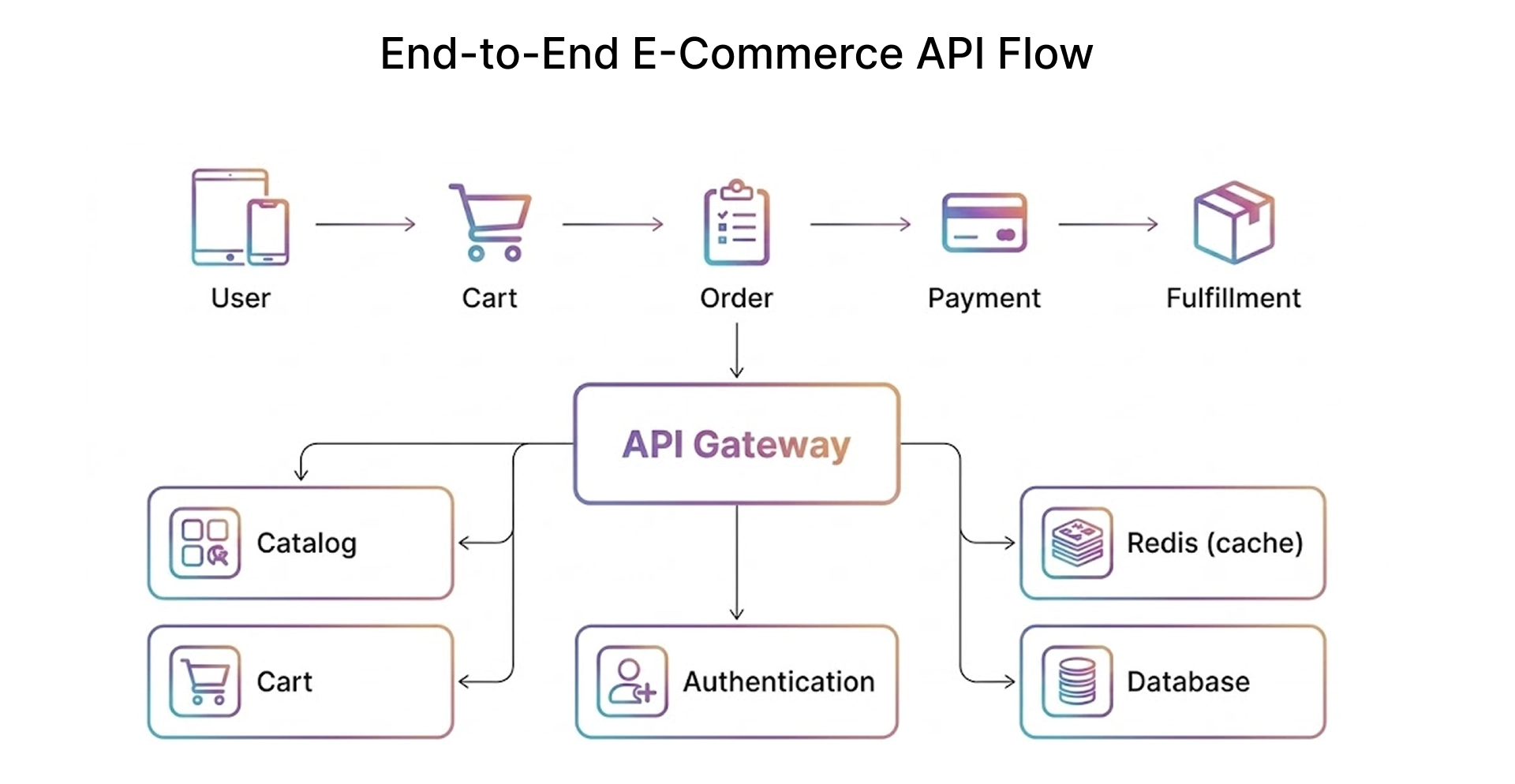
In a typical e-commerce application, a single purchase runs through five API calls in sequence:
- Cart API - checks product availability and current price
- Authentication API - validates the session token via OAuth 2.0
- Payment API - processes the charge
- Inventory API - reduces stock after the sale is confirmed
- Fulfillment API - triggers the shipment
Prioritize Testing Based on Financial and Operational Impact
But, as most know, not all APIs are created the same, and that's part of the reason that so many API testing initiatives are dead on arrival. You need to know how much a broken API will impact the business, so we must categorize our APIs:
1. Business Critical (Financial, compliance):
- Transaction processing service
- Authentication/authorization
- Anti-fraud service
- Must be tested at 100% (security + functional)
- Must be part of CI/CD
2. Operational Critical:
- Order processing service
- Inventory look-up
- Shipment tracking service
- Requires heavy integration and performance testing (latency and throughput)
3. Non-critical to the business:
- Reporting endpoints
- Admin interfaces
- Require lower-level regression testing due to lower risk
Apply the API Testing Pyramid for Better Coverage
The API Testing Pyramid describes where to concentrate effort across three layers. The core idea: most of your tests should be cheap and fast; expensive end-to-end tests should be saved for the scenarios where failure is most costly.

Create End-to-End Workflows for Complex Microservices
Individual service tests passing does not mean your microservices work together. You need to verify that operationally connected workflows succeed end-to-end, not just that each piece passes in isolation.
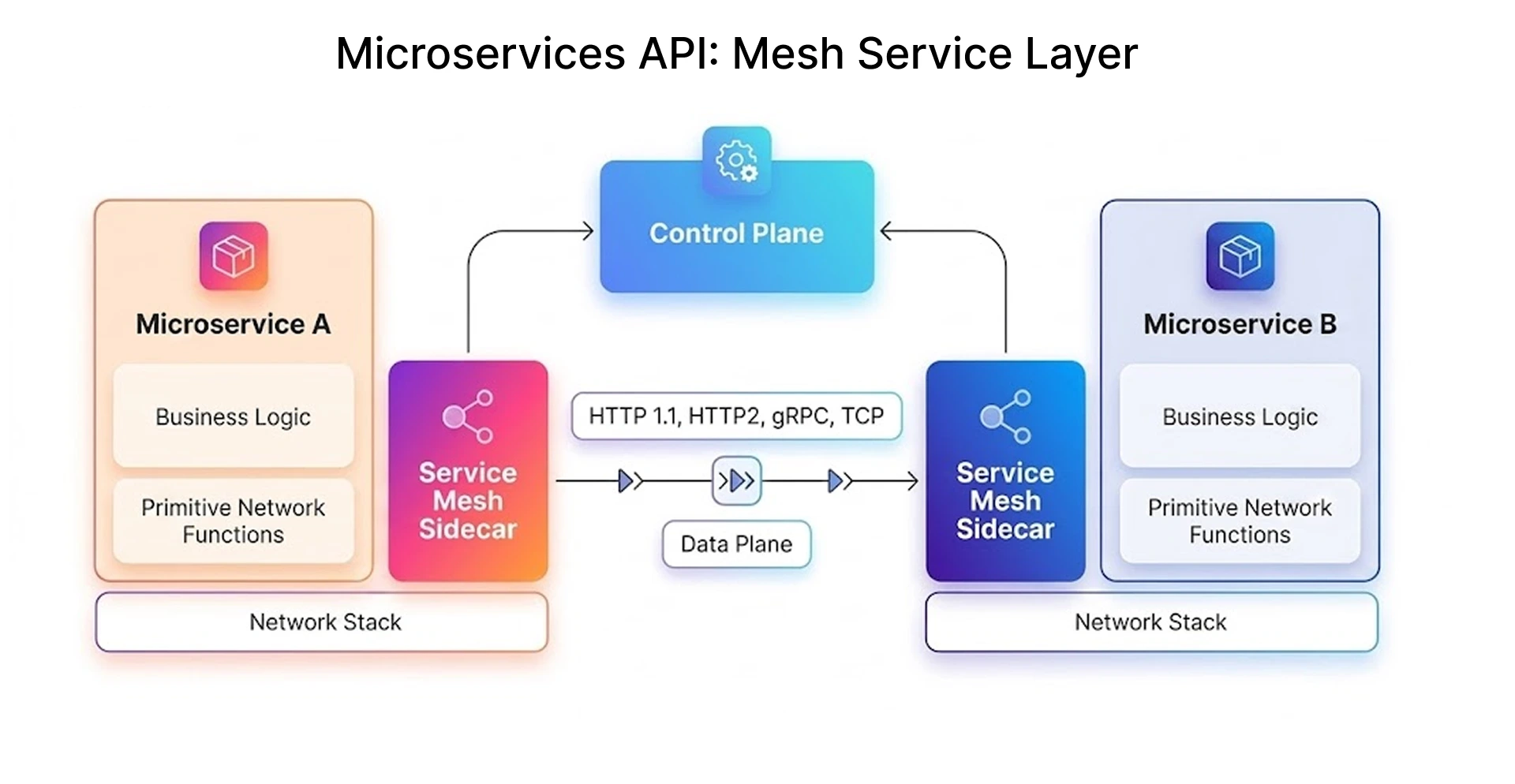
Two approaches that actually help:
- API Mocking & Service Virtualization: Simulate downstream services or third-party systems (a delayed payment processor, for example) so you can test scenarios without hitting real services.
- AsyncAPI Contracts: For event-driven microservices, define message schema expectations (JSON Schema) alongside standard HTTP request validation. This prevents ambiguity in event payload structure before production deployment.
Prepare for Third-Party Failures of APIs
Most production failures originate not from internal code but from third-party dependencies, such as payment gateways returning unexpected responses or identity providers timing out.
There are 3 ways to mitigate this:
- Pact Contract Testing: Verify integration contracts for APIs between consumer and provider teams before production, ensuring that changes won't affect the existing system. Especially powerful when the consumer and provider teams work separately.
- Load Testing: Evaluate your systems' resilience against high traffic using tools like Apache JMeter or Gatling to identify the breaking point for the service under stress. Test critical workflows rather than single endpoints.
- Fallback Validation: Before production rollout, simulate critical third-party failure points, such as broken JSON data structures or response codes of 4xx or 5xx. Your system should handle it gracefully, or fail less gracefully in production.
7 Proven Best Practices for High-Impact Results
Focus on High-Value Paths and Critical Edge Cases
Not all test cases are equally valuable. Focus on where failures cost the most: payments, login, and critical data sync. Those are the paths worth the most thorough coverage.
Beyond the happy path, you need to explicitly test what happens when things go wrong at critical points. What does your payments API return when the authorization header is missing? What happens if inventory sends back malformed data during checkout?
These scenarios get missed by basic endpoint tests and tend to surface only after go-live.
Happy Path - POST /payments returns 200 with a valid transaction ID:
@Test
public void testSuccessfulPayment() {
given()
.header("Authorization", "Bearer valid-token")
.contentType("application/json")
.body("{ \"amount\": 100, \"currency\": \"USD\" }")
.when()
.post("/payments")
.then()
.statusCode(200)
.body("status", equalTo("success"))
.body("transaction_id", notNullValue());
}Critical Edge Case - Missing Authorization Header returns 401:
@Test
public void testMissingAuthHeader() {
given()
.contentType("application/json")
.body("{ \"amount\": 100, \"currency\": \"USD\" }")
.when()
.post("/payments")
.then()
.statusCode(401)
.body("error", equalTo("Unauthorized"));
}Validate Data Consistency Across Multiple Systems
A 200 response does not guarantee valid data. In a microservices architecture, the order API may confirm payment while the inventory service fails to update stock, creating inconsistencies that only appear later during fulfillment.
Data consistency testing involves validating and reconciling state changes across multiple systems after API execution. The focus is not just on response codes, but whether the system state is correctly updated across services. This requires cross-service validation rather than isolated endpoint checks.
Use Contract Testing to Ensure That Integration Doesn't Fail
The components in microservice architectures evolve independently. The provider team may make a slight modification to a response format, delete a field, or change an error code, and suddenly the consumer service fails at runtime.
This is a schema version drift, and is one of the more common causes of silent integration failures.
The Pact contract testing tool helps avoid this issue by enabling consumers and providers to define and verify the expected interface in an independent manner, catching breaking changes in CI/CD before a deployment can cause an outage.
Validating responses against an OpenAPI schema provides another layer of protection against drift if OpenAPI specifications are already in use.
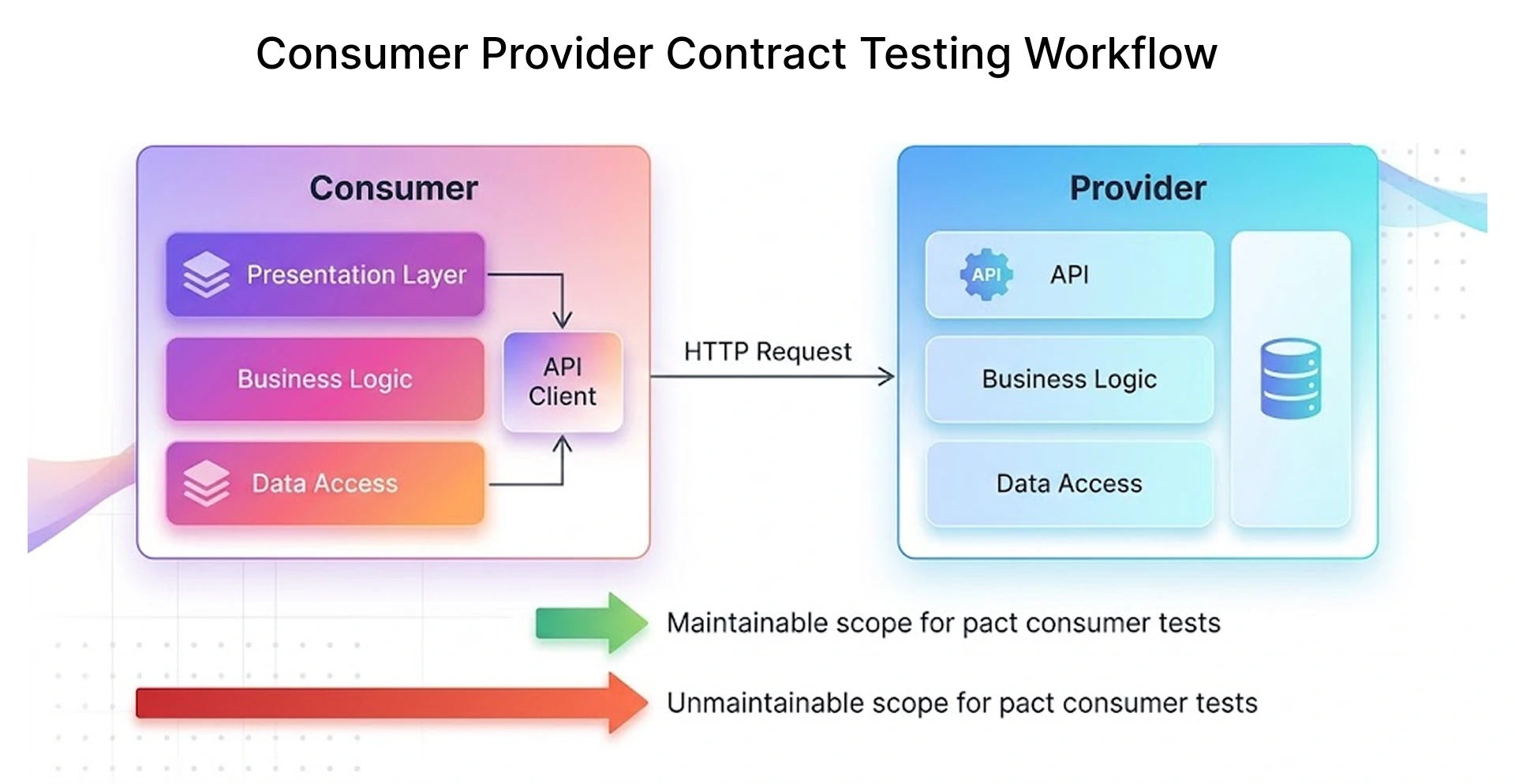
The consumer-provider Pact diagram shows the maintainable scope (green - API client to API layer) vs unmaintainable scope (red - full consumer to database chain) for Pact consumer tests.
Automate Regression Testing of Your Critical Workflows with Appropriate Tools
It simply is not feasible to test your critical API workflows with manual regression tests as release cadence increases. The best approach to automated regression is a tool capability aligned with workflow risk tiers.
Make sure your automated regression suite stays focused. Automating every test causes a maintenance burden that impacts your release speed. Automate your Tier 1 and Tier 2 workflows from your risk register to get trustworthy coverage where failure is important.
Treat Security and Performance as Functional Risks
Separate late-stage API Security Testing and performance testing always miss key security vulnerabilities. As a risk-based methodology, these are functional requirements on high-risk endpoints; they have to be built into the CI/CD pipeline from day one, not slapped on at the end.
On Tier 1 APIs, security weaknesses such as SQL injection and Cross-Site Scripting have to be found pre-deployment. Integrate security tests into your pipelines with OWASP ZAP and StackHawk for continuous security verification. Penetration Testing on critical endpoints can verify that your authentication and authorization logic is robust enough under actual attack conditions.
API Load Testing and Stress Testing with Apache JMeter or Gatling will determine if critical workflows meet your response time and throughput expectations, instead of letting production decide.
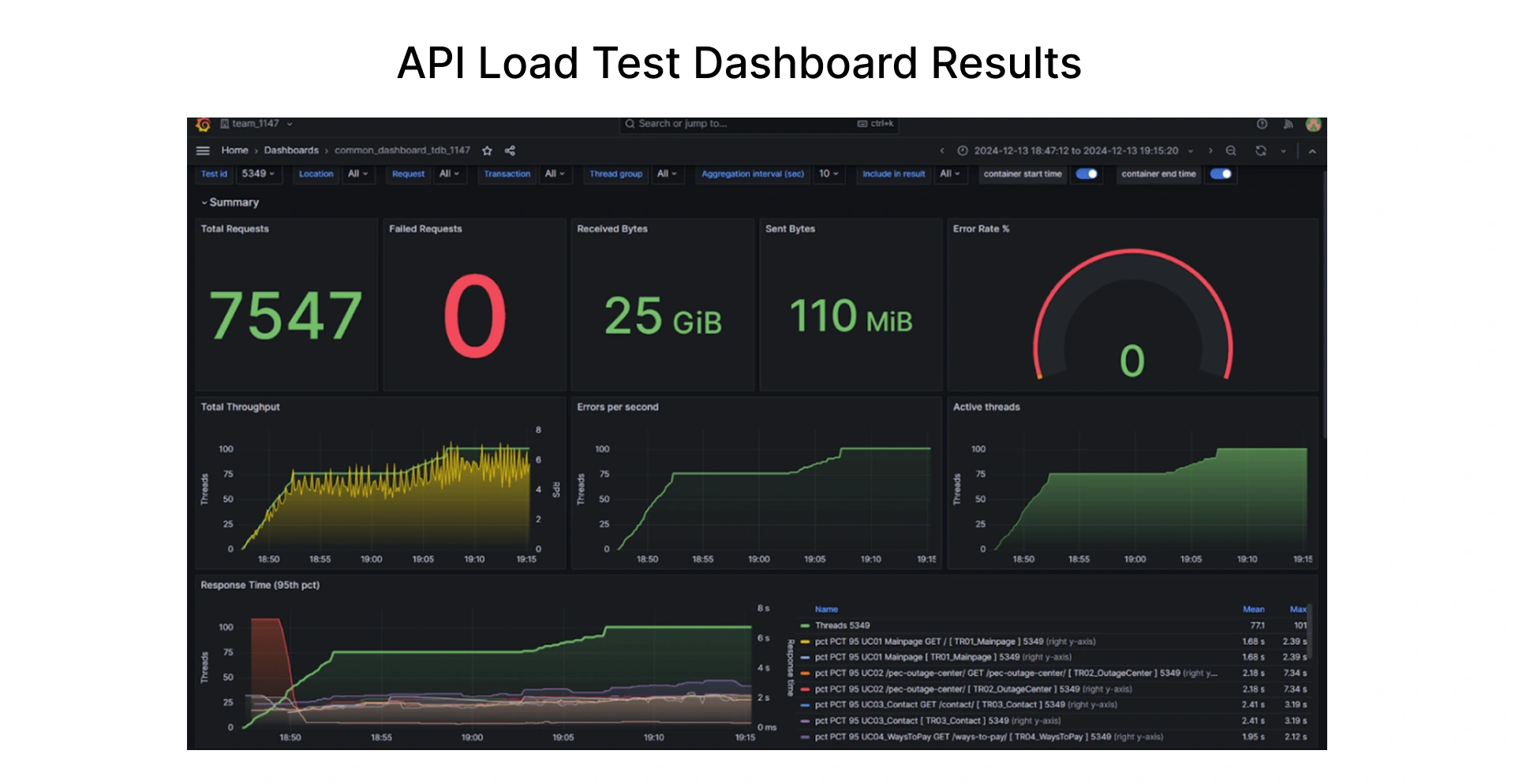
Build Observability to Identify Drift in Real-Time
Tests performed before release help us find known risks. Once deployed, continuously monitoring can help find what you missed or what changed post-release.
Set response time thresholds of your T1 API on load tests, then continuously monitor and alert on anything that has drifted from your baseline in production. Drift in error rates or response time, for example, is easily identified and can be mitigated before a problem arises, as compared to simply letting the metrics worsen post-deployment.
We can monitor the uptime of critical endpoints; the slightest deviation here is an instant sign of something that changed.
Future-Proofing Your Strategy with Observability and Monitoring
A failed pre-deployment test should never be your only concern. Post-release usage can and will change, external dependencies will behave in unpredictable ways, and unexpected changes to your schemas may not be accounted for by your test suites.
To use your observability for action, you'll need three key components:
- Real-time Monitoring: Define thresholds of your T1 APIs in your load tests. Use these thresholds to understand when your average payment API load time of 280ms is hitting 620ms consistently, alerting you before your users do.
- Error rate monitoring: Notice when your authentication API is seeing a massive spike in 401 responses, which can be attributed to either expiring tokens or a broken schema. For a fulfillment API, the same large spike in 503 responses should be alarming, indicating that a downstream service is possibly failing.
- Contract Drift Detection: Test live API responses against your contract (OpenAPI or AsyncAPI) on a continuous basis to get alerted for and be able to fix any schema drifts and breaking changes that could potentially impact your downstream services.
Observability takes your API testing strategy into the production environment, where the most interesting monitoring can take place.
Frugal Testing: Enabling Risk-Based API Test Strategy
In Frugal Testing API test engagements, the most common deficiency that we find is Tier 1 critical path coverage. Teams have fairly comprehensive endpoint coverage, but not automated validation of critical end-to-end paths (e.g., checkout-to-fulfillment, auth-to-session). Those are the places where defects reside-and where flat API testing doesn't (because it treats the reporting endpoint as an equal with the payment processor endpoint).
During one load test engagement, there were ~1,800 APIs that were under 500ms at baseline. Within about 15 min of steady load, response times increased, and there were <500 APIs that were still under 1,500ms. This degradation would have gone to production without load testing in the pipeline.
What we find in our work in this area includes:
- API testing strategy: Risk-tiered test coverage aligned to business workflows instead of just endpoints
- Test Automation Services: Automated regression on T1 and T2 workflows integrated seamlessly into your CI/CD pipeline
- API Testing Services: Testing for contract, performance, and security issues is built into the development process and not an afterthought
- Continuous monitoring: Production observability that can find behavior drifting before it impacts users
Conclusion: Building a Resilient API Ecosystem Around Business Risk
The number of endpoints tested within an API testing strategy isn’t nearly as important as whether the business-critical flows responsible for generating revenue, security, and compliance are properly tested.
All seven principles outlined within this document, from business-risk-based prioritization to contract testing, production-like data, and continuous monitoring, all have one thing in common: testing is focused on the workflows that would have the largest business failure costs.
By taking this approach to their test strategy development, development teams are now able to:
- Catch integration failures within their CI/CD pipeline, instead of during production
- Uncover schema drifts before they impact other downstream systems
- Define performance thresholds before a surge in traffic trips over system capacity
The difference between a resilient API ecosystem and a fragile system is rarely the tool it’s whether tests are designed around business losses that cannot be absorbed.
People Also Ask (FAQs)
Q1.How do you measure the effectiveness of a risk-based API test strategy?
Ans: The effectiveness of a risk-based API test strategy shows in production outcomes, not coverage numbers. Track production defects, failure rates in Tier 1 APIs, and incident impact. Coverage dashboards turn green while checkout flows have gaps nobody noticed. The right metric is fewer production incidents in critical workflows.
Q2.How do you handle versioning in API test strategies?
Ans: API versioning in test strategies requires contract testing and version-aware test suites that validate old and new versions simultaneously. Without this, a renamed or dropped field breaks a dependent service that nobody caught because tests only covered the new interface.
Q3.Can risk-based API testing be applied in Agile or DevOps environments?
Ans: Risk-based API testing fits Agile and DevOps better than broad coverage approaches because it forces a clear decision: which APIs need deep testing on every release? Embedding Tier 1 and Tier 2 tests into CI/CD pipelines keeps critical workflows validated without slowing releases.
Q4.How does the API test strategy differ for a microservices architecture?
Ans: Testing each service in isolation confirms individual services work not whether they work together. A risk-based approach shifts focus to service interactions, contract testing, and end-to-end workflow validation like checkout-to-fulfillment or auth-to-session-state. That is where integration failures actually live.
Q5.How do you handle dependencies between multiple APIs during testing?
Ans: Dependencies between multiple APIs can cause cascading failures if one service breaks mocking, service virtualization, and contract testing prevent this. Testing against live dependencies alone creates flaky results based on external system state, not actual code issues. Mocking lets you simulate failure conditions without needing them to actually occur.



.webp)


