

A new Claude model landed, and within hours, engineering Slack channels filled with screenshots, not benchmark charts. That's usually the tell: a release that changes how work actually gets done makes people show each other what happened, not quote a score. Claude Sonnet 5 is one of those releases.
This piece breaks down what changed for AI in software testing, upgrade by upgrade, through two lenses: what shifts inside testing itself, and what shifts in how teams hand work to each other. Some changes live inside Sonnet-class models, others only show up next to the heavier Opus-class models above them, and a few only matter once you factor in cost and turnaround time.
What's Actually New in Claude Sonnet 5
Sonnet 5 follows a fast run of releases: Claude Sonnet 4.6 in February, Opus 4.6 not long after, and Opus 4.8 in May. Talk of a Sonnet 4.8 never shipped; the jump went straight to Sonnet 5. Every upgrade below reads through two lenses: testing and agentic coding workflow.
- Verify before you quote it: Confirm every capability claim against Anthropic's release documentation on the Claude Platform before repeating a number in a client deck, since model cards move fast and a figure that was accurate in February can already be stale.
Upgrade 1: Generative AI in Software Testing
Generative AI in software testing shows up first in the most tedious part of a QA engineer's week: writing test cases from a spec, one requirement at a time, work that used to be entirely manual.
- What Changes for Test Case Authoring: A QA engineer now reviews AI-generated test cases against acceptance criteria instead of writing every one from scratch. The blank-page problem disappears, but the judgement call on real coverage still sits with a person.
- What Changes for Product-to-QA Handoff: A testable suite exists almost as soon as the spec does, cutting the round trips that usually eat the first week of a sprint, so testing starts closer to day one.
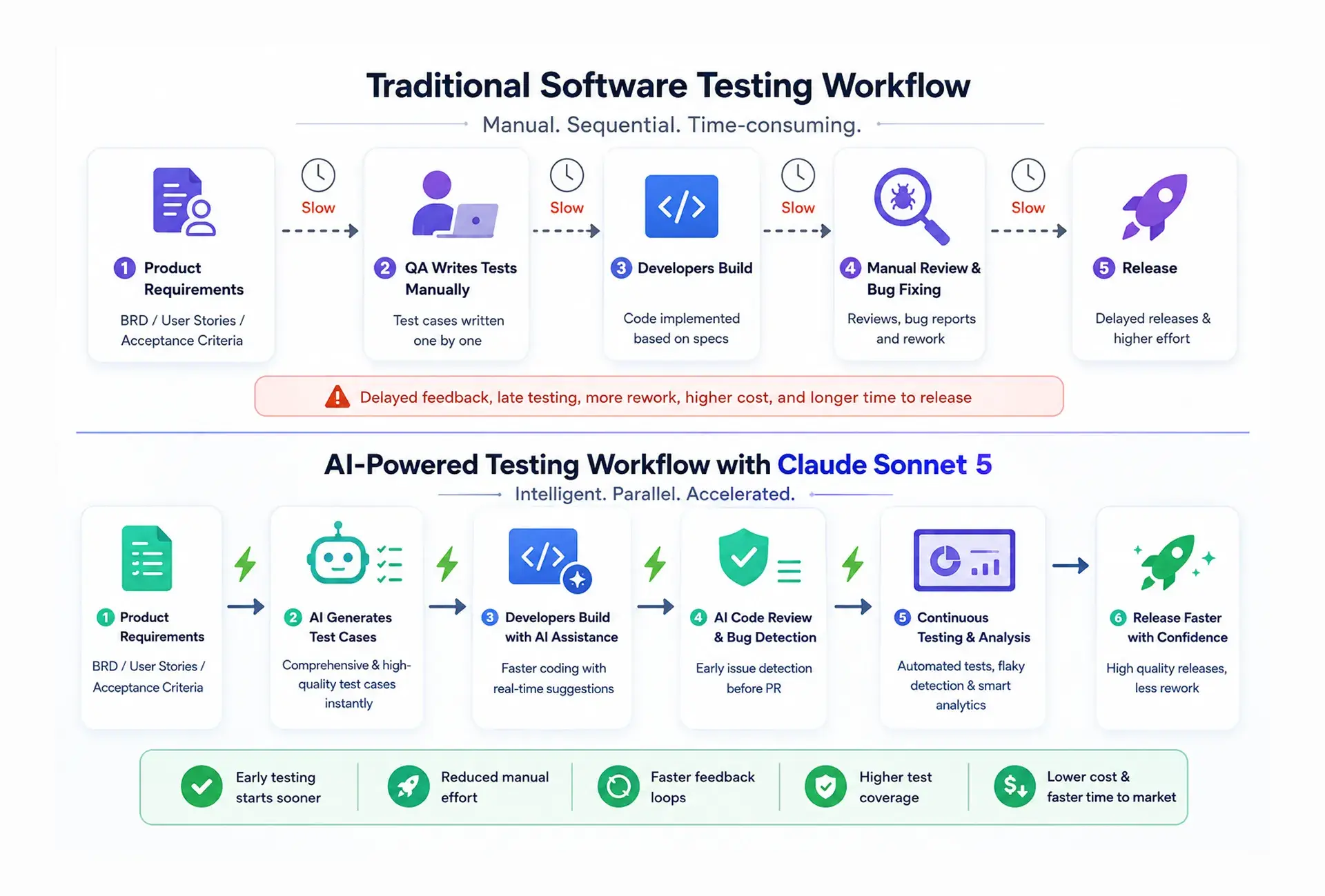
Upgrade 2: AI in Test Automation
Self-healing scripts and flaky test detection aren't new inside agentic development environments, but earlier versions needed constant supervision before anyone trusted them in production. Better reasoning inside Sonnet-class models changes that.
- Flaky Test Detection in Practice: A pipeline flags a flaky login test, traces it to a timing issue, and reroutes it before it blocks a release. It also catches cases where malformed data in a test fixture, not the application itself, caused the failure.
- What This Frees Up for the Team: Hours once spent on selector maintenance now go toward exploratory testing and release readiness reviews, which is the actual return on AI in test automation, not just a faster tool.
Upgrade 3: AI-Powered Code Review
A stronger model catches more logic errors on the first pass, and edge-case handling has improved noticeably across large repositories, especially where dependencies span several services.
- Where AI Review Still Falls Short: It still misses architectural decisions and business-logic bugs that only make sense with full context of the system. That gap is why modern AI coding practices still route the final call to a senior engineer, not the model.
- How This Changes PR Cycle Time: Review stops being the bottleneck and becomes a fast filter before a human looks at what's left. Inside Claude Code, that filter now runs earlier in the workflow, ahead of the pull request.
Upgrade 4: AI Unit Test Generation
Generation quality now extends beyond end-to-end suites into unit tests themselves, quietly changing how teams think about coverage gaps in legacy code.
- Where This Changes the Technical Debt Conversation: Backfilling a legacy module used to mean weeks of manual effort for a return nobody could justify. Now that effort is cheap, teams are finally willing to close coverage gaps they'd been avoiding, since the maths, not the code, got easier.
Upgrade 5: AI in DevOps and CI/CD
Model improvements aren't limited to the testing layer either; they reach pipeline-level decisions too, covering build failure triage, log analysis, and release risk scoring.
- Reading CI Failures Faster: Log analysis that used to take an engineer twenty minutes now takes two, helped along by better latency trends across the model's output tokens, shortening the loop to root cause.
- What This Means for On-Call and Incident Response: Fewer people get pulled into the bridge call once triage moves faster. Time to resolution drops, not because any one engineer works faster, but because fewer people need to be looped in.
Upgrade 6: AI Coding Assistant Comparison (LLM Code Generation)
For a QA or engineering reader, three things matter when comparing assistants: how reliably one handles a large codebase, how well it fits into existing tooling, and whether the generated code needs heavy rework before it ships. The model picker inside the Claude Platform weighs Sonnet-class models against Opus-class models on input tokens and price, since Claude Sonnet 4, Sonnet 4.6, and Sonnet 5 all suit different task types at different price points.
Upgrade 7: What This Means for Enterprise AI Adoption
The first six upgrades are mostly about how the work gets done. This one is about who gets to decide it should happen at all.
- Questions to Ask Before Rolling This Out: Ask how data is handled, what audit trail exists, and how output gets validated before anything ships, including whether cybersecurity tasks sit under a dedicated security service or stay bundled with general QA.
- How Roles Shift When AI Handles More of the Routine Work: QA engineers, PMs, and support staff all spend less time on repetitive execution. What replaces that time is judgement calls and escalation handling, the real organisational cost and gain.
Worth grounding this in numbers rather than vibes. The World Quality Report found AI use among QA teams roughly doubled in two years, from 22% to 45%, a shift that tracks with how fast the tooling itself has improved. A separate 2026 survey found most testing teams lean on AI for generating test cases, yet fewer than one in five use it for risk identification.
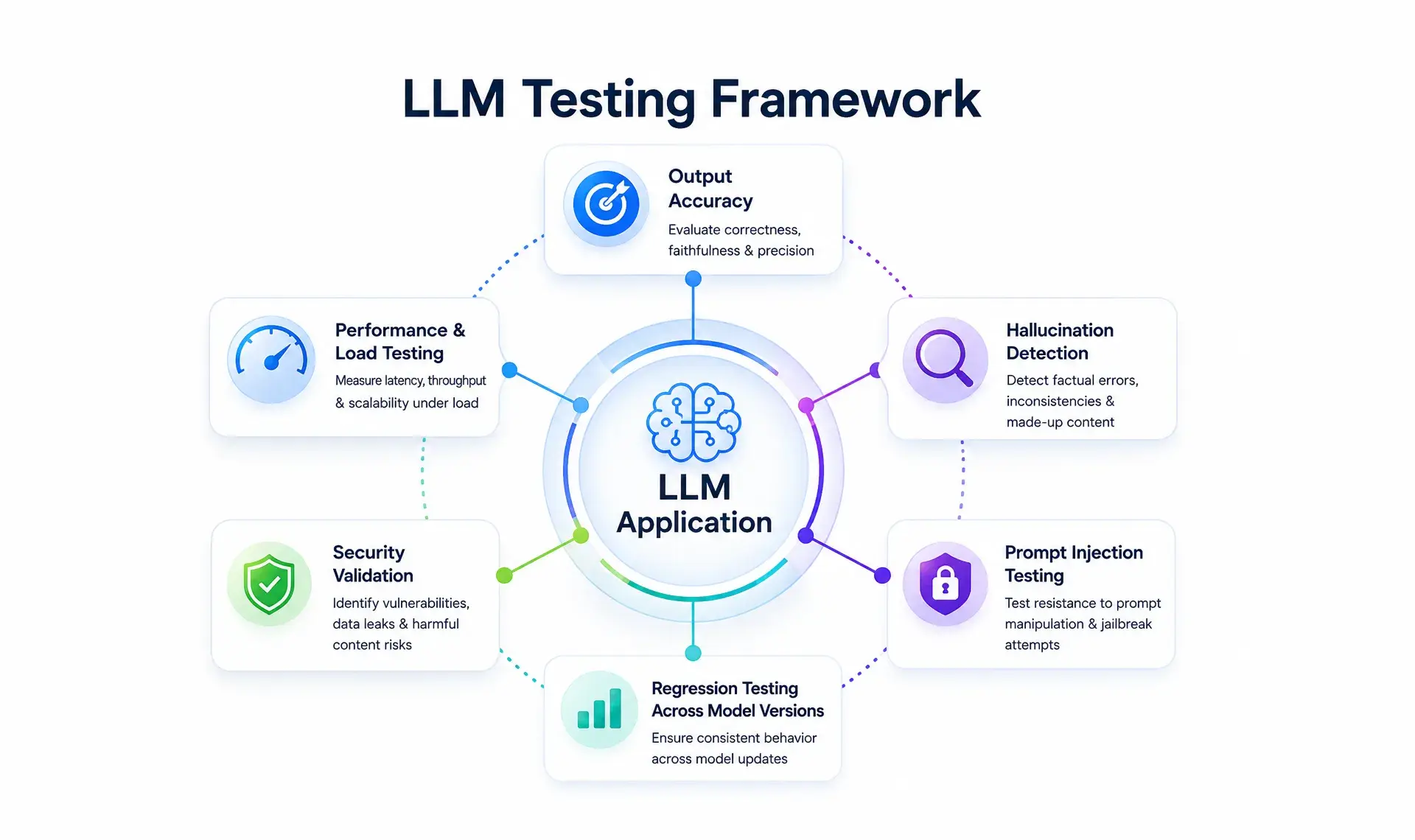
How Frugal Testing Tests LLMs and AI-Powered Applications
Model upgrades like this one create a specific problem: how do you actually know a new version hasn't quietly broken something your users depend on? Reasoning mode adds another variable, since a model that reasons differently across versions can answer the same prompt differently, a drift manual spot-check won't catch, especially under load or with edge-case inputs.
What Our LLM Testing Approach Covers
Our approach covers output accuracy, hallucination and factuality checks, prompt injection resistance, and regression testing across model versions. One engagement's eval suite caught a 12% accuracy drop before an upgrade reached production, functioning as much like a security solution as a QA one, built into a reusable eval harness the client owns.
Who This Is For
This is for teams shipping a chatbot, copilot, or RAG pipeline to production, or anyone upgrading models without a clear way to measure what might break. If your evaluation process still stops at manual spot-checks, that's usually exactly where the risk is hiding.
.webp)
Conclusion
None of this is really a testing story or an engineering story on its own. It's a workflow story. AI in software testing is one visible piece of a larger shift in how specs become features and how teams hand off knowledge work to each other, sprint after sprint, and teams tracking what Sonnet-class and Opus-class releases actually change will spend less time firefighting later.
People Also Ask (FAQs)
Q1. What does Claude Sonnet 5 change beyond just coding?
Ans: It shortens handoffs across product, QA, and support teams, not only engineering output, and gives teams a faster route from a written spec to a testable, working feature overall.
Q2. Can AI fully replace manual QA testing?
Ans: No. It augments test generation and flaky test detection, but human review stays essential for architectural judgement, business context, and the edge cases models still routinely miss in practice.
Q3. How does an AI model upgrade affect teams outside engineering?
Ans: It speeds up spec-to-build handoff for product teams, shortens support ticket triage, and cuts incident response time by pulling fewer people into a bridge call during outages.
Q4. How do I evaluate AI code review tools for my team?
Ans: Check accuracy on your own codebase, integration effort with existing tooling, and false positive rate before rolling anything out further, then pilot it on one real pull request.
Q5. Is generative AI test case creation reliable for production systems?
Ans: Yes, with a mandatory human review step before anything ships. Treat generated cases as a draft against acceptance criteria, not a finished suite ready for release.




