

A QA lead at a 90-person SaaS company once told us their team spent three days every sprint just fixing broken selectors. The product team had pushed a UI refresh, the Playwright suite had no idea, and the AI generation tool they'd bought six months earlier was still producing test scripts against a DOM that no longer existed. Static prompts, zero live context, same old problem wearing a new badge.
That is the gap the Model Context Protocol closes. Not by replacing your test automation framework, but by giving AI agents something they have never had before: live access to your application, your test data, and your CI/CD pipelines in a single, standardised protocol. In the context of AI in test automation, this is the architectural shift that actually matters in 2026.
This guide gives you the architecture, the trade-offs, and a clear picture of where Playwright MCP fits in your pipeline and what it takes to move from AI automation testing hype to a production-viable agent layer.
What Is MCP and Why Does It Matter for AI in Test Automation
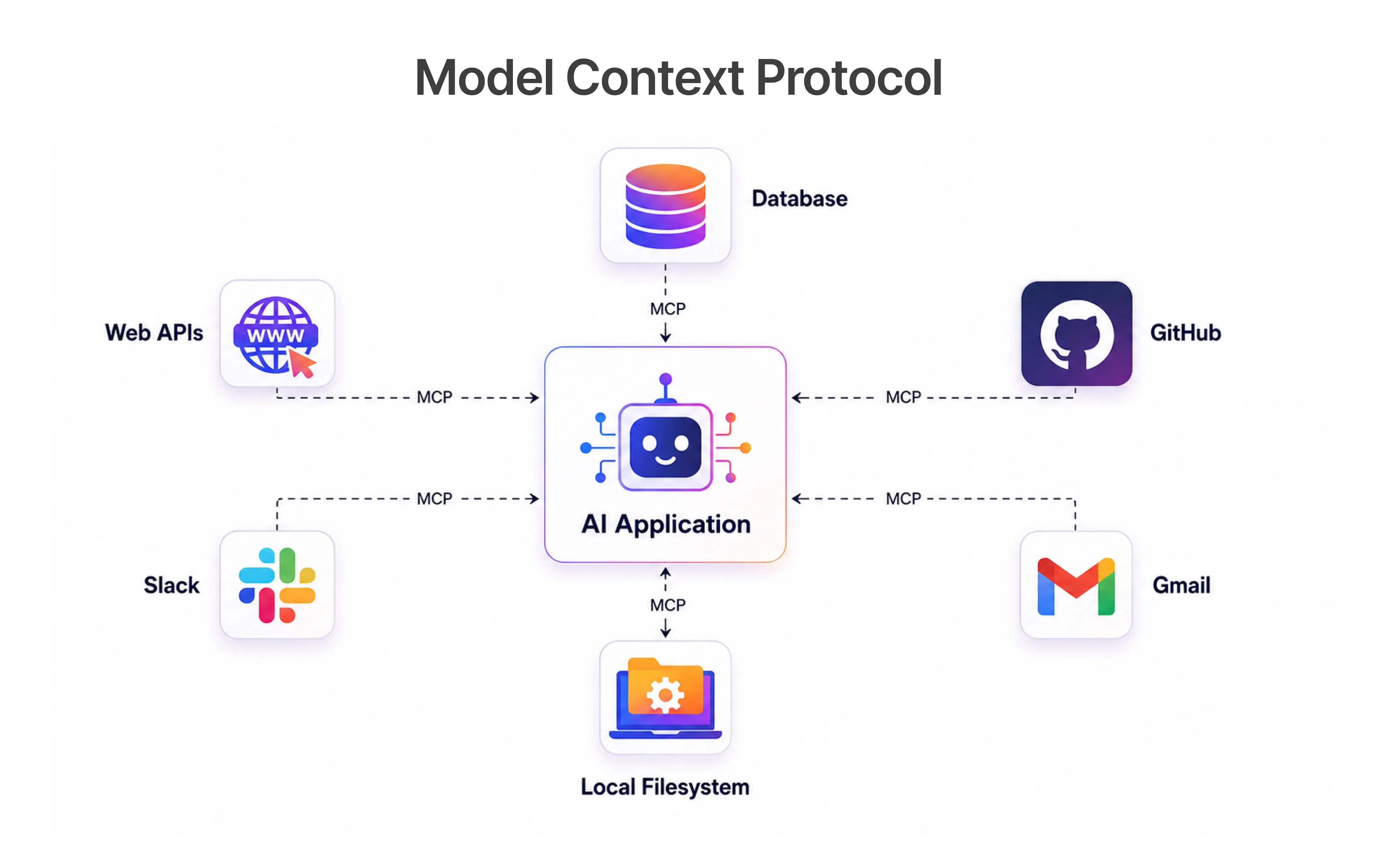
The Model Context Protocol is an open standard - first published by Anthropic and now community-governed - that lets AI models call external tools and read live, structured context from real systems: test environments, databases, CI logs, browser state. It is what distinguishes autonomous artificial intelligence agents from one-shot generators.
Most AI automation testing tools available today are prompt-based generators. You feed in a user story or a URL screenshot, the large language model outputs a test script, and that is the end of the interaction. There is no feedback loop. The model cannot observe what the application does when the test runs. It cannot re-locate a moved button, re-read a failed assertion log, or adjust a selector when the DOM changes.
MCP changes that architecture entirely. An MCP client sits between the AI agent and a set of MCP servers - each server exposes a specific system: a browser, a database, a CI/CD pipeline, a test management tool. The agent can query any of these systems mid-session, observe the result, and act on it. That is what AI-first QA capabilities actually look like at the protocol level.
2026 is the practical inflection point for two reasons. First, the community MCP server ecosystem - covering browsers, GitHub Actions, Azure DevOps, and application programming interface endpoints - has reached a level of stability that production QA testing can rely on. Second, Playwright now ships with first-class MCP support via the Playwright MCP server, meaning teams already on Playwright can integrate an agent layer without migrating frameworks. The Playwright Model Context Protocol integration in particular has matured from an experimental plugin into a documented, production-ready interface.
MCP vs Traditional AI Test Generation Plugins
The distinction matters because the market is full of tools that describe themselves as "AI automation testing" but operate as one-shot generators. GitHub Copilot, VS Code Copilot, and Claude Code are excellent at producing test code inside an editor or terminal context - Claude Code in particular is strong at scaffolding entire test files from a spec - but none of them execute tests, observe live application state, or self-correct based on a failure. They are AI-assisted authoring tools, not AI test agents.
An MCP-connected agent running via Playwright MCP can do something fundamentally different: it executes a browser test, reads the accessibility tree of the resulting page state, identifies that a button has moved, updates the selector, and retries the step, all within a single session. That is what self-healing test automation actually looks like - not a marketing badge, but a protocol-level feedback loop.
The Microsoft Learn Docs MCP Server extends this further: it exposes Microsoft documentation as live context the agent can query mid-session, which matters when your test suite covers Microsoft 365 integrations, Microsoft Graph API endpoints, or Azure SDKs. Instead of the agent working from stale training data on those APIs, it reads current documentation and generates assertions against the actual schema.
How MCP Changes the Architecture of Your Test Automation Framework
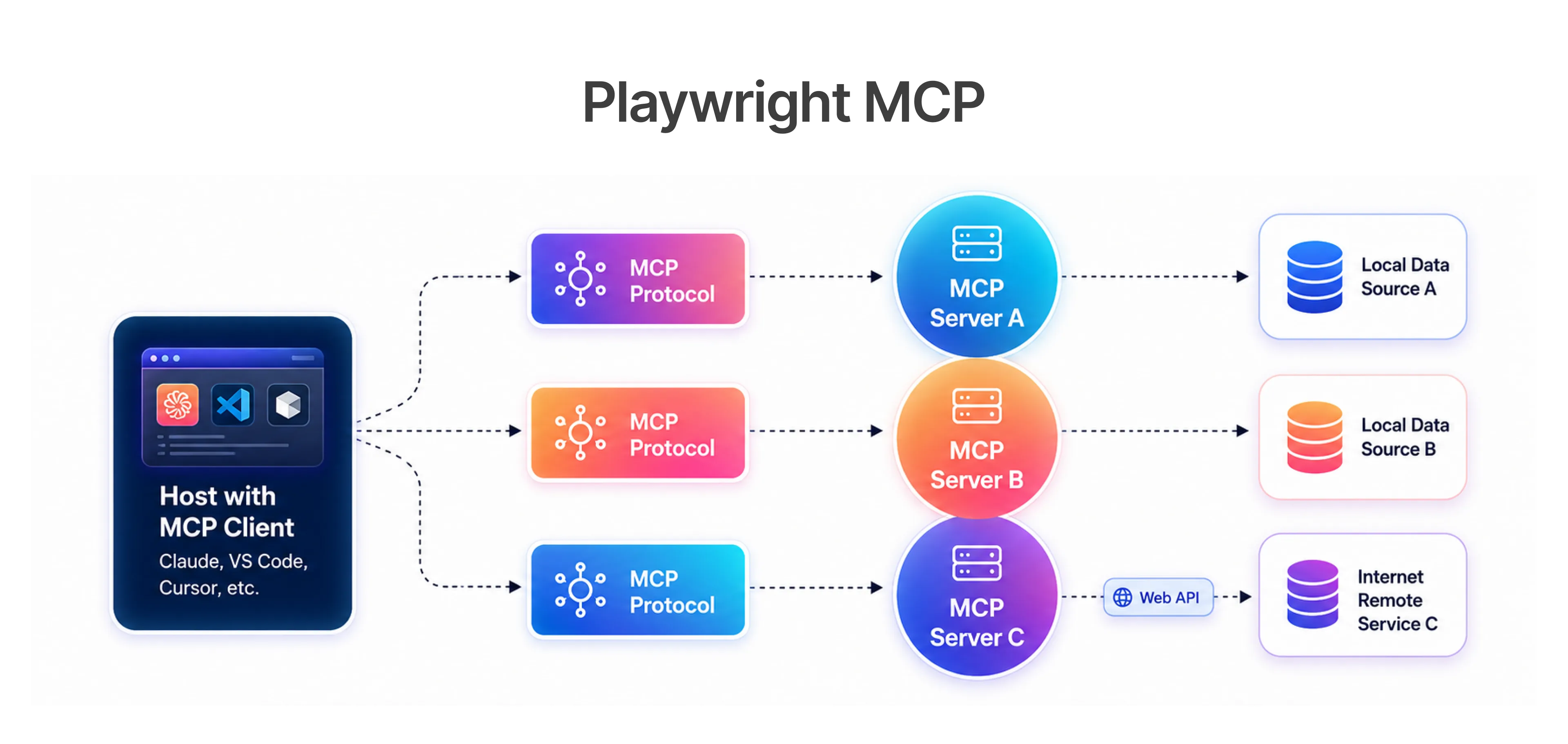
The architecture shift is simpler than it looks. You are not replacing Playwright Test or Selenium WebDriver. You are adding an orchestration layer above them.
The stack, from top to bottom:
- AI agent (Claude, GPT-4, or a task-specific model) receives an instruction or a failure signal
- MCP client translates the agent's intent into tool calls against registered MCP servers
- MCP servers expose specific systems: a Playwright MCP server for browser control, an API server for API testing, a CI server for GitHub Actions run data, a database server for test fixtures
- Test environment receives the actual browser or API commands and returns real application state
These components form what practitioners increasingly call test agents - autonomous processes that combine model reasoning with live tool access to execute, observe, and correct test runs without human intervention at each step. The Playwright Model Context Protocol layer is where most teams start, because browser test maintenance is typically the highest-friction part of QA testing.
Your existing Playwright or Selenium suite stays in place. Integration testing, end-to-end testing, and API testing all continue to run through the same framework. What changes is that an AI agent can now observe failures, reason about them with live context, and take corrective action.
Context window management is the engineering discipline this introduces. Every MCP server call returns structured data - DOM snapshots, assertion results, log lines - and that data flows into the model's context for the current session. The practical pattern: pass only the failing test's selector chain, the relevant DOM subtree, and the last three log lines from the CI/CD pipeline run. Everything else is noise.
Connecting Playwright MCP and Selenium Pipelines
For teams on Playwright, the Playwright MCP server (maintained by Microsoft) exposes browser control, page navigation, element interaction, and screenshot capture as MCP tools. A Playwright MCP connection lets test agents execute Playwright Test steps, read the resulting accessibility tree, and iterate on failures without context-switching out of the session. Playwright APIRequestContext is available through the same MCP interface, which means the agent can run API testing assertions alongside browser tests in a single coordinated session.
The Playwright CLI remains available for headless execution in CI/CD pipelines. The MCP layer adds the agent's reasoning loop on top of standard Playwright execution.
For Selenium WebDriver teams not yet ready to migrate, the equivalent pattern is a custom MCP server wrapping Selenium Grid. It exposes the same categories of tools - navigate, interact, observe - but proxies them through your existing Selenium infrastructure. Migration is not a prerequisite for getting value from MCP test agents.
Feeding CI/CD and Test Data Context Through MCP
The second category of MCP servers is less visible but often more valuable: servers that expose test data, environment state, and pipeline signals to test agents.
A practical setup includes an MCP server that surfaces: active feature flags for the environment under test, pytest fixtures or test data seeds relevant to the current suite, and p95 latency metrics from the last three GitHub Actions runs. The agent uses this context to decide whether a failure is a genuine regression, environment flakiness, or a timeout caused by rate limits on an external dependency.
Rate limits deserve specific attention here. When test agents run parallel execution across a large suite, they can exhaust API rate limits on staging services - particularly for Microsoft Graph API integrations, Twilio API endpoints, and third-party SaaS services your application depends on. An MCP server that exposes current rate limit headroom lets the agent throttle parallel execution dynamically rather than hammering dependencies until they fail.
This is where AI in QA testing moves past script generation and into actual engineering reasoning. The agent is not guessing. It has the same context a senior engineer would pull up before triaging a failure.
The bottom line: The MCP architecture does not make your test suite smarter. It gives test agents enough context to act on failures the way a smart engineer would - and that is what reduces QA testing maintenance overhead in regression suites.
Building an MCP-Powered AI Test Automation Stack
Here is how a production-ready MCP stack for a mid-size engineering team is actually assembled.
Core components:
- Playwright MCP server for browser-based end-to-end testing, visual testing baselines, and Playwright component testing of isolated UI units
- API testing MCP server for schema validation, payload validation, contract testing, API regression testing, and Playwright APIRequestContext coverage
- CI/CD MCP server connected to GitHub Actions for run history, failure logs, and parallel execution metrics
- Test management MCP server for reading test case metadata and writing results back to Test Collab - including Test Collab's test plan assignments, Test Collab execution statuses, and Test Collab defect linkages
- Security MCP server for running security scanning checks against the staging environment as part of automated QA cycles, covering OWASP API Security Top 10 surface areas
Permission scoping is not optional. The agent gets read access to staging environment logs, read access to pytest fixtures, and write access only to test result artefacts and failure annotations. It does not touch production. Security Permissions boundaries here are the difference between a useful agent and a liability.
The maintenance argument for this architecture is straightforward. In a Page Object Model suite of 300+ browser tests, the most common maintenance task is selector repair after UI changes. An agent with live DOM access via Playwright MCP can identify broken selectors, propose replacements based on the current accessibility tree, and flag them for human sign-off. Teams we have worked with see roughly 40% fewer manual selector-fix cycles in the first quarter after MCP integration.
Page Object Model suites in particular benefit because the agent can update locators at the page object layer directly rather than hunting through individual test files - a single Page Object Model fix propagates across every test that uses that page object.
Parallel Execution and Rate Limit Management
Parallel execution is where most teams hit their first production problem with MCP-based test agents. Running 50 browser sessions in parallel via Playwright MCP is feasible. Running them all against the same staging database while simultaneously triggering API testing calls against rate-limited third-party services is not.
The practical architecture uses parallel execution across isolated test workers, each with its own pytest fixtures scope, its own Test Collab test run record, and its own MCP session. The orchestration layer controls concurrency based on the rate limit headroom exposed by the API testing MCP server. When a Microsoft Graph API endpoint reports near-limit headroom, the agent backs off parallel execution on that test category automatically.
Parallel execution also interacts with visual testing: running visual testing comparisons in parallel across multiple Playwright MCP sessions requires a shared baseline store, typically an Azure storage accounts container, so every parallel worker compares against the same reference screenshots rather than generating conflicting baselines.
Choosing Open-Source MCP Servers vs Custom Builds
For standard systems - browsers via Playwright MCP, GitHub Actions, Azure DevOps, VS Code for local development context - use community MCP servers. Azure storage accounts are particularly useful as a destination for test artefacts, Allure reports, and visual testing failure screenshots. An MCP server wrapping Azure Blob Storage lets test agents write results directly without a separate upload step in your pipeline.
Azure SDKs and Azure AI Search integrations in the Microsoft Build ecosystem expose further context: Azure AI Foundry deployment metadata, Azure AI Search index state for RAG evaluation runs, and Microsoft 365 API surface coverage for enterprise application test suites.
For proprietary internal systems - a legacy test orchestration platform, an internal API testing gateway, a custom CI system - build a thin MCP wrapper. Expose the four or five signals test agents actually need: run status, failure reason, environment config, and the pytest fixtures seed in use.
The Microsoft Learn Docs MCP Server is worth calling out specifically for teams building on Azure: it gives test agents live access to current Azure SDKs documentation, Microsoft 365 API references, and Microsoft Graph API schema - so when contract testing assertions break after an API version bump, the agent can read the updated spec and propose corrected assertions rather than just reporting a failure.
The bottom line: Stack selection is not the interesting engineering problem here. Parallel execution discipline, rate limit management, and permission scoping are.
MCP-Based Agents vs Traditional Automation vs Current AI Testing Tools
.webp)
Testing AI Applications and Models With MCP-Driven Pipelines
There is a second use case that does not get enough attention: using MCP to test the AI features inside your own product, not just to test the product itself.
If your application uses large language models - a generative AI feature, a RAG system, a recommendation engine, a customer support bot - traditional QA testing cannot validate non-deterministic outputs. You cannot write an exact-match assertion for a model response. You need an evaluation framework.
MCP gives you the infrastructure for that eval loop. An MCP server exposes model inputs, model outputs, and ground-truth datasets as structured data. The test agents run comparison tests across prompt versions or model versions, applying schema validation to confirm output structure and using semantic search or LLM-as-a-judge evaluation to assess response quality without exact matching.
RAG evaluation specifically benefits from MCP architecture. A RAG evaluation run needs to track retrieval precision (did the agent pull the right chunks?), response accuracy (did the answer match ground truth?), and latency (did Azure AI Search return results within acceptable bounds?). An MCP server that exposes all three signals lets test agents run structured RAG evaluation pipelines rather than one-off manual checks. The RAG evaluation results write back to Test Collab as a dedicated test run, giving QA leads a consistent record of model quality over time.
RAG systems and vision models need separate evaluation tracks. For RAG evaluation, the relevant signal is retrieval precision alongside response accuracy, surfaced via Azure AI Search. For vision models, test agents can use Playwright component testing to observe how visual outputs render in the application and compare against a visual baseline stored in Azure storage accounts.
Property-based testing adds another layer for AI applications: instead of fixed test cases, the agent generates input variations across a property space and checks that output invariants hold. This is particularly valuable for testing AI applications where the input distribution is wide and edge cases are hard to enumerate manually. Property-based testing combined with LLM-as-a-judge evaluation catches failure modes that hand-authored test cases miss.
Debugging AI-Driven Test Failures: Flakiness vs Model Drift
When an MCP-driven test agent fails, there are three possible explanations, and conflating them wastes significant QA cycles.
Environment flakiness - the testing infrastructure had a transient issue, often related to rate limits or parallel execution contention. Clean pass on immediate retry with no input change.
Application regression - the product changed in a way that breaks expected behaviour. Consistent failure across multiple runs and environments.
Model output drift - the AI feature's outputs have shifted, either because the underlying model was updated or because the prompt context changed. Structural or semantic deviation from baseline outputs with no corresponding application code change.
The logging setup that makes this triage tractable: every MCP-driven test run records the prompt sent, the model version in use, the environment config, and the full output alongside the assertion result. With that context in Allure reports or Test Collab, a human reviewer can triage a failure in minutes. Allure reports in particular integrate well here - Allure reports carry the full step-by-step execution trace from the Playwright MCP session, so the reviewer sees exactly which MCP tool call preceded the failure.
Machine Learning model versioning and Azure AI Foundry deployment metadata should be part of this logging surface if your team uses Azure AI infrastructure. Azure SDKs and Azure AI Search integrations expose this via MCP servers, and Azure AI Foundry's model registry gives test agents a stable reference point for which model version was active during a given test run. That traceability is what makes RAG evaluation reproducible rather than a snapshot at a single point in time.
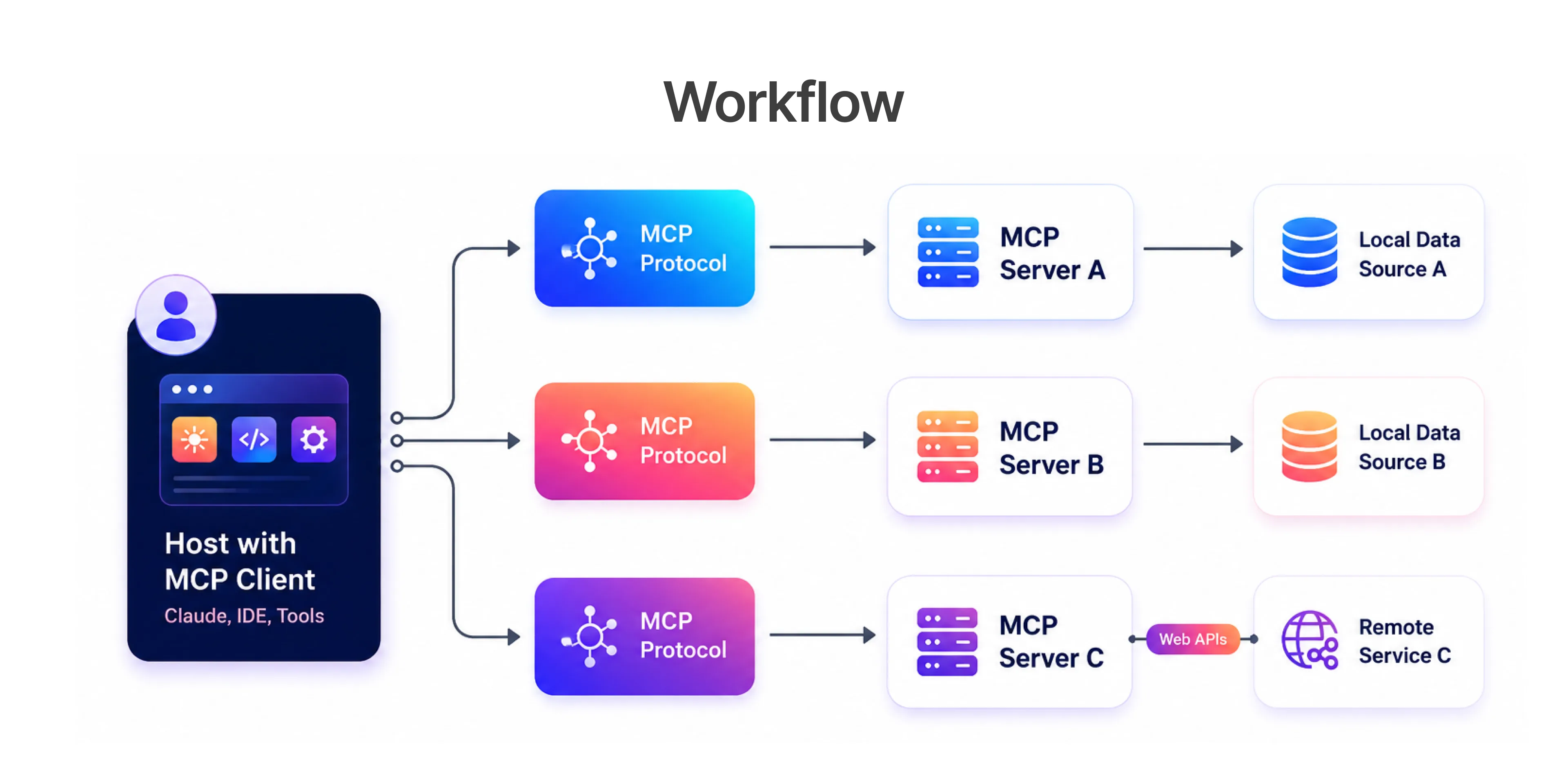
How Frugal Testing Builds Your MCP-Powered Test Automation Framework
We run an AI-Augmented Test Automation engagement specifically for teams who want to introduce MCP-based test agents without spending two quarters on internal R&D.
The delivery is structured in four phases. Weeks one and two: audit of the existing framework, mapping which test categories - browser tests, API testing, integration testing, contract testing - carry the highest maintenance burden. Weeks three and four: we stand up the MCP server layer - Playwright MCP server for browser and visual testing, an API testing MCP server with Playwright APIRequestContext coverage, a CI/CD server connected to GitHub Actions or Azure DevOps, and Test Collab integration so every agent-driven run writes results back automatically. Weeks five and six: we integrate test agents into the team's existing CI/CD pipelines, configure parallel execution with rate limit guards, and validate against the live regression suite. Ongoing: we tune pytest fixtures scoping, review Allure reports with the team on a fortnightly cadence, and extend Test Collab coverage as the agent layer grows.
At the end of the engagement, the client owns the documented MCP architecture, the configured servers, and an internal team that knows how to extend it.
What Our MCP Test Automation Engagement Looks Like
The profile this is built for: teams running Playwright or Selenium suites of 200 or more tests, releasing weekly or faster, where QA testing maintenance time is consuming headcount that should be going into new test development.
The two trigger situations we hear most often: "our regression suites break on every UI change and someone spends a day every sprint fixing selectors," and "we want to pilot AI automation testing but we do not know how to scope the context without making the agent unreliable."
If either of those describes your current QA cycles, the conversation is worth having.
Who This Is For
This is not for teams at the beginning of their test automation framework journey. Playwright MCP and MCP-based test agents add the most value when you already have a suite worth maintaining - when the maintenance cost itself has become the constraint.
If you are earlier in the journey, start with test automation strategy and come back to MCP when your suite reaches the scale where agent-driven self-healing test automation makes economic sense. Cloud native deployments that release multiple times per day are typically the context where the ROI is most immediate - the higher your release cadence, the faster QA testing maintenance compounds as a cost.
"More tests is not always better. A smaller, reliable suite with a Playwright MCP-driven self-healing test automation layer outperforms a large, fragile suite maintained by hand every time."
.webp)
Conclusion
AI automation testing has been a credible promise for three years and a production reality for about six months. The gap between the two was always the same problem: AI QA testing tools that could generate test code but could not observe, reason about, or correct against a live application.
Playwright MCP closes that gap for browser and API testing. The Microsoft Learn Docs MCP Server closes it for teams building on Azure and Microsoft 365. Test Collab integration closes it for QA testing teams who need traceability, not just execution. Allure reports close it for engineers who need to understand what the test agent actually did, step by step, before a failure.
The Model Context Protocol does not make AI in test automation simple. It makes it tractable. For teams running 200-plus test suites on cloud native deployments, where QA testing maintenance overhead is the dominant cost, the architecture is sound and the tooling is mature enough to deploy.
People Also Ask (FAQs)
Q1. What is MCP (Model Context Protocol) in the context of QA testing?
Ans: MCP is an open standard that lets test agents query live systems - browsers, databases, CI/CD pipelines - during a QA testing session rather than working from static prompts. The agent can observe real application state, read failure logs, and self-correct without a human in the loop.
Q2. Does Playwright MCP replace Playwright Test or Selenium WebDriver?
Ans: No. The Playwright MCP server sits above your existing framework as an orchestration layer. Playwright Test and Selenium WebDriver continue to execute the tests; Playwright MCP gives test agents the interface to drive and observe them.
Q3. How is MCP-based AI automation testing different from tools like GitHub Copilot or Claude Code?
Ans: GitHub Copilot, VS Code Copilot, and Claude Code are AI-assisted authoring tools - they generate test code in an editor or terminal. MCP-based test agents execute tests, observe live results via Playwright MCP, and self-correct based on actual application state. They operate at runtime, not authoring time.
Q4. How do you handle non-deterministic outputs when testing AI applications?
Ans: Use schema validation for structure, RAG evaluation metrics for retrieval accuracy, property-based testing for input variation coverage, and LLM-as-a-judge evaluation for response quality. Exact-match assertions do not work for generative AI outputs - assertion strategies need to match the non-determinism of the system under test.
Q5. How does parallel execution work with Playwright MCP test agents?
Ans: Each test agent runs in an isolated Playwright MCP session with its own pytest fixtures scope. The orchestration layer controls concurrency based on rate limit headroom exposed by the API testing MCP server - so agents back off parallel execution automatically when Microsoft Graph API or other staging dependencies approach their rate limits.






